Airbnb网络抓取指南. 方法、挑战和最佳实践
网络抓取Airbnb(一个全球短期租赁和体验平台)涉及自动从房源中提取数据,以揭示平台本身无法获得的见解。它对于分析市场、跟踪竞争对手,甚至计划个人旅行都很有用。然而,Airbnb的反抓取防御措施和动态设计使其成为一项技术要求很高的任务。本指南将教你如何使用Python成功抓取Airbnb房源。
Dominykas Niaura
最后更新: 12月 29日, 2025年
10 分钟阅读
为什么要抓取Airbnb数据?
Airbnb数据有助于了解短期租赁市场、旅行者行为以及各城市的房产表现。无论你是分析师、投资者还是开发者,抓取Airbnb都可以让你收集通过公共仪表板或API无法直接获得的结构化信息。以下是一些最常见的用例:
- 竞争情报。房产所有者和租赁经理可以监控竞争对手的房源,分析设施、评论、入住率和定价策略,并完善自己的服务。
- 定价分析。通过跟踪每晚房价、季节性变化和预订频率,分析师可以确定最佳定价模型,以最大化入住率和收入。
- 市场趋势。抓取的数据有助于识别新兴目的地、旅行者偏好的变化,以及新房产类型的崛起(例如精品工作室或生态小屋)。
- 情感分析。评论和客人反馈揭示了旅行者对某些地区或房产类型的喜好或不满,这对房东和旅游战略家都很有价值。
- 个人旅行规划。除了研究之外,旅行者还可以使用抓取的Airbnb数据来寻找独特的住宿,筛选隐藏的宝藏,或比较多个目的地的定价趋势。
抓取Airbnb的挑战
抓取Airbnb并不像发送几个HTTP请求那么简单。该平台使用一系列技术措施来保护其数据并为合法用户维护性能:
- 反机器人和反抓取防御。Airbnb依赖JavaScript密集型页面、动态内容加载和基于行为的检测系统。如果没有浏览器渲染,抓取工具可能无法加载基本元素。此外,当流量看起来是自动化的或来自单一来源时,IP封锁和验证码是常见的。
- 网站结构不断变化。Airbnb经常更新其HTML布局和API端点,这很容易破坏现有的抓取工具。维护可靠的数据提取需要持续监控和代码调整。
- 速率限制。即使请求成功,Airbnb也会限制在给定时间范围内允许来自单个IP或会话的操作或页面加载数量。如果管理不当,这可能导致数据集不完整或临时禁令。
Airbnb网络抓取的方法
收集Airbnb数据没有唯一正确的方法,你的选择取决于技术技能、规模以及更新频率。实际上,大多数项目属于两类之一:构建自己的抓取工具或使用现成的API服务。
DIY自定义抓取工具
如果你熟悉代码,用Python构建自己的抓取工具可以让你完全控制Airbnb数据的收集和处理方式。
Playwright、Selenium和Beautiful Soup等库可以让你加载房源、浏览页面并提取结构化详细信息,如标题、价格、位置和评分。Playwright和Selenium都可以渲染JavaScript密集型页面并在浏览器中模拟真实用户行为,而Beautiful Soup则解析生成的HTML以进行干净、有组织的数据提取。
DIY抓取工具可以从小型研究任务扩展到强大的数据收集管道,只要你维护它并适应Airbnb不断变化的网站结构。它比使用第三方工具需要更多的实际操作工作,但作为回报,它提供了灵活性、透明度以及根据你的确切需求定制抓取工具的能力。
使用第三方网络抓取API服务
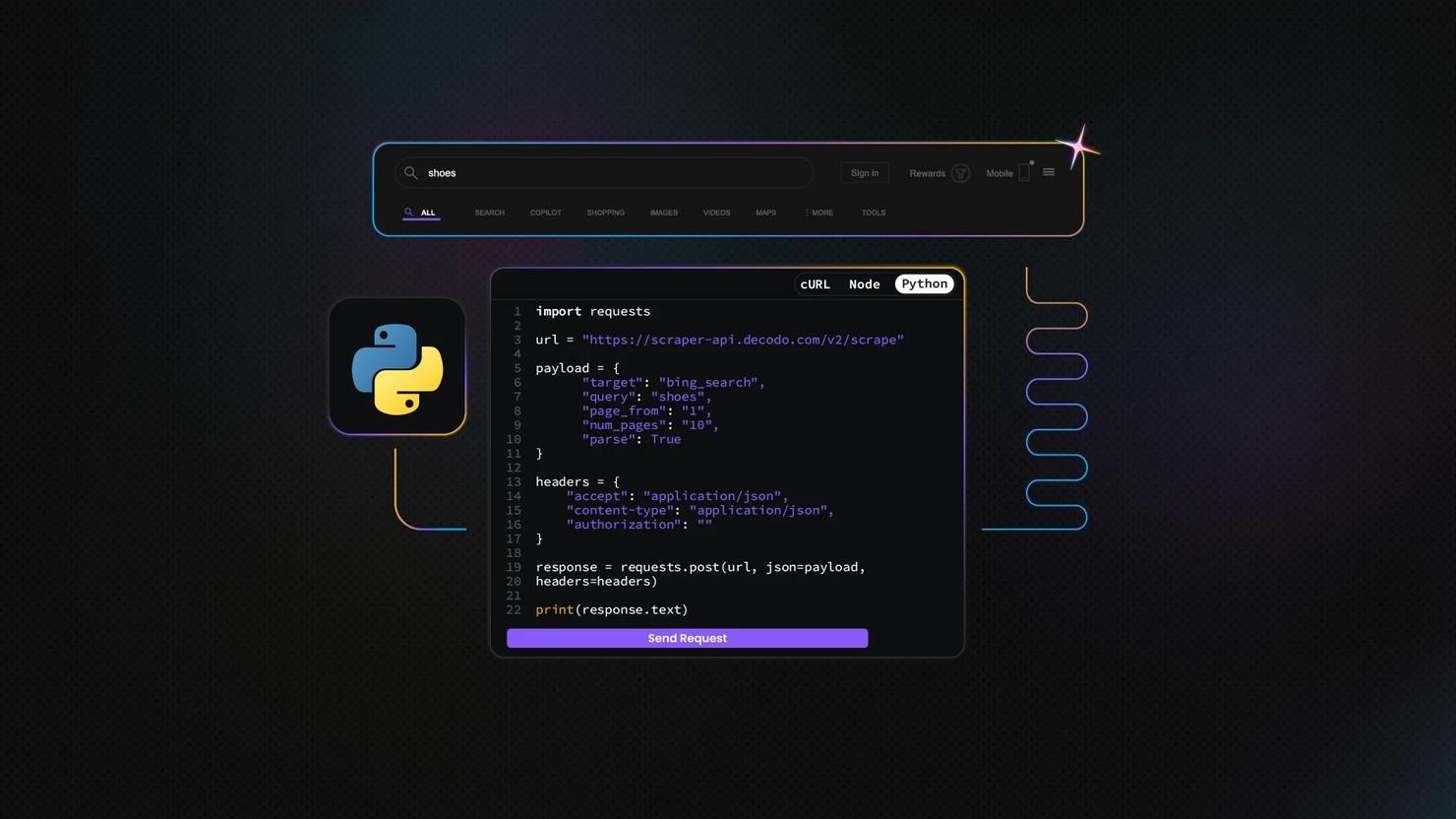
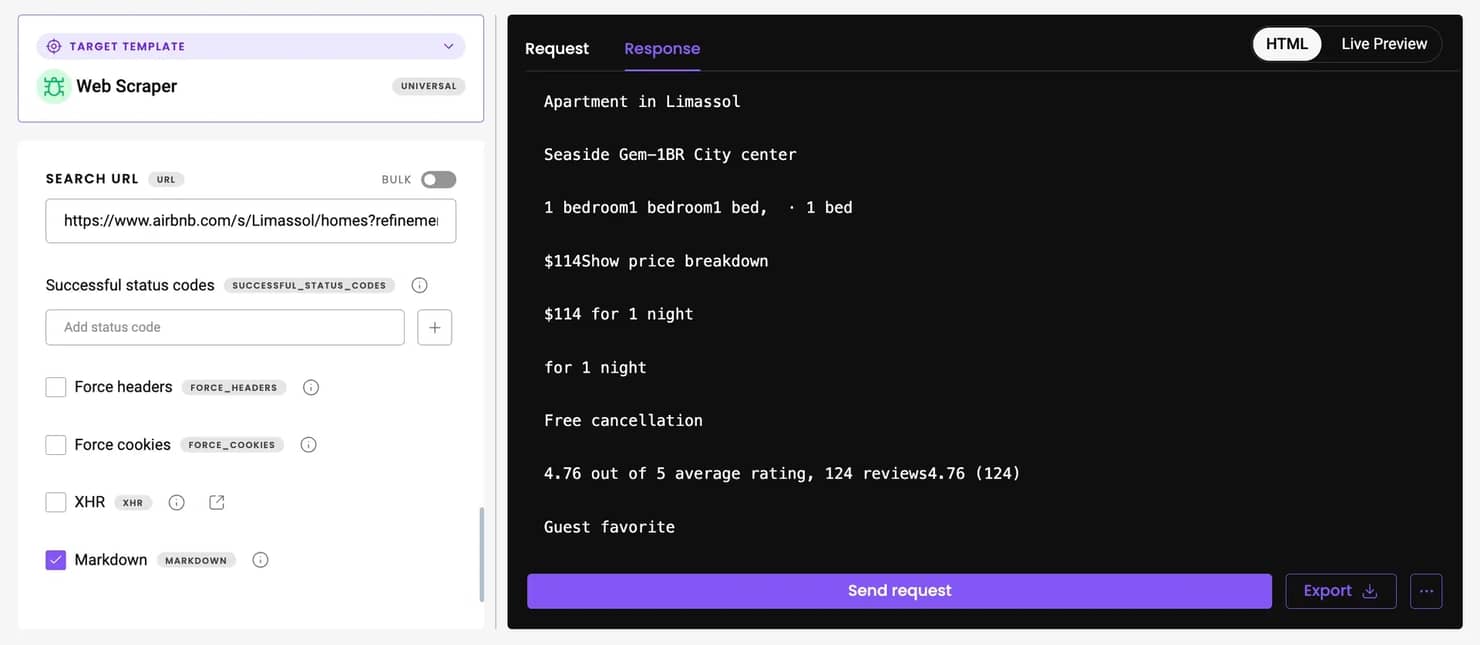
或者,你可以依赖为你处理繁重工作的抓取API,例如代理轮换、JavaScript渲染和速率限制。Decodo的网络抓取API等服务允许你指定URL并以HTML、JSON或CSV等格式返回数据。
网络抓取API包含100多个适用于流行网站的现成模板。由于Airbnb还不是其中之一,你需要使用Web(通用)目标,它返回任何页面的HTML。然后,你可以使用与我们稍后将在本指南中构建的Playwright脚本类似的逻辑来解析此输出。
如果你更喜欢开箱即用的可读格式,请启用Markdown选项,Airbnb页面特别适合使用它,因为它们包含很少不必要的标记,并以清晰、面向文本的结构呈现数据。
逐步指南. 抓取Airbnb房源
让我们构建一个Python抓取工具,大规模收集Airbnb房源数据。此脚本使用Playwright进行浏览器自动化,自动处理分页,并包含反检测功能以保持抓取工具顺利运行。
先决条件
在运行抓取工具之前,你需要一些基本要素来准备你的环境:
安装Python。你需要Python 3.7或更高版本。通过在终端中运行此命令来验证你的版本:
安装Playwright。Playwright库支持浏览器自动化。运行以下命令安装它并下载浏览器二进制文件(Chromium、Firefox、WebKit):
其他依赖项。脚本使用内置的csv、time和re模块,因此你不需要为这些模块安装任何其他包。
设置动态住宅代理。Airbnb应用严格的速率限制和反机器人过滤器。使用动态住宅代理有助于你保持不被检测并防止IP禁令。下面的示例脚本配置为使用Decodo在"gate.decodo.com:7000"的动态住宅代理网关,但你可以调整仪表板参数(例如位置,这也决定了Airbnb结果中显示的货币)以生成自定义代理字符串。
Decodo提供成功率为99.92%、平均响应时间低于0.6秒的动态住宅代理,并提供3天免费试用。以下是入门方法:
- 在Decodo仪表板上创建账户。
- 在左侧面板上,选择动态住宅代理。
- 选择订阅、Pay As You Go 计划或申请3天免费试用。
- 在代理设置选项卡中,配置你的位置和会话首选项。
- 复制你的代理凭据以集成到抓取脚本中。
查找你需要的数据
Airbnb使用JavaScript动态加载其内容,因此你不能仅通过简单的HTTP请求获取页面HTML。你需要在浏览器中检查渲染的HTML。
在Chrome或Firefox中打开任何Airbnb搜索结果页面,在页面上的任意位置右键单击,选择检查元素,然后使用选择工具单击房源。你会注意到每个房产都出现在<div itemprop="itemListElement">容器内。在内部,你会发现标题、价格、评分和描述等数据点分布在多个元素中。
抓取工具将使用Playwright的定位器系统定位这些结构:
- 标题和描述从每个容器内的文本内容中提取。
- 评分和评论数使用正则表达式识别,匹配"4.95 (123)"等格式。
- 价格数据来自类为umg93v9的元素。
- 房源URL取自href属性包含"/rooms/"的锚标签。
为避免重复,抓取工具使用每个房源的房间ID(从其URL中提取)来跟踪已收集的房产。
构建抓取工具
抓取工具围绕单个类AirbnbScraper构建,这使逻辑保持有组织且易于扩展。
- extract_listing_data。此方法接收房源容器元素并解析其文本以提取标题、描述、评分和价格。正则表达式用于数字字段。如果提取失败,它返回None以保持数据完整性。
- 分页。scrape_airbnb方法处理页面之间的导航。它滚动到分页区域,找到下一页链接(类c1ackr0h),并自动加载它。你可以调整max_pages参数来控制深度。
- 反检测措施。为了减少封锁,抓取工具使用隐身参数在无头模式下启动Chromium,通过注入的JavaScript屏蔽webdriver属性,设置随机的、真实的用户代理字符串,包括随机睡眠间隔以模拟人类浏览,并自动处理Cookie横幅。
保存和使用数据
有许多方法可以保存抓取的数据,但在此脚本中,结果存储在干净的CSV文件中以便于分析。save_to_csv()方法导出标题、描述、评分、评论数、价格和URL等字段,同时排除仅用于去重的内部ID。保存后,主函数打印前几个房源的预览以确认数据已正确捕获。
导出后,CSV可以加载到Pandas中进行更深入的分析,跟踪价格趋势、评分分布或比较社区和设施。这使得根据评分和评论识别表现最佳的租赁变得容易,或者定期运行抓取工具并监控价格和可用性如何随时间变化。
脚本完全可定制:你可以更改max_pages、更新目标URL,或扩展extract_listing_data()方法以包含其他详细信息,如房东信息或设施。其模块化结构使其易于随项目目标发展。
完整的Airbnb房源抓取工具脚本
你可以复制下面的代码,将其保存为.py扩展名,然后从终端或IDE运行它。插入代理凭据和要抓取的Airbnb搜索URL后,只需启动脚本,它会提示你输入要收集多少页。抓取完成后,它将在终端中显示抓取数据的小样本,并自动将完整数据集保存到CSV文件中以进行进一步分析。
在此示例中,我们正在抓取塞浦路斯利马索尔在圣诞假期期间的Airbnb房源。抓取工具收集你请求的页面数,并编译有关标题、价格、评分和评论数的数据。默认情况下,显示的货币取决于你的代理位置,但你可以通过在目标URL后附加参数(如"¤cy=EUR")来覆盖它,例如:
抓取完成后,输出显示为在终端中预览的整齐结构化表格,如下所示:
扩展规模的高级技巧
随着你的Airbnb抓取项目超越小型实验,保持稳定性和避免检测成为关键。大规模收集需要的不仅仅是一个简单的脚本,它需要仔细关注代理、JavaScript渲染和反机器人防御。
使用代理和轮换IP
Airbnb主动限制来自单个IP地址的流量,因此大规模抓取只有使用代理才可持续。动态住宅代理是最可靠的选择,因为它们使请求看起来来自真实用户。定期轮换IP(每个请求或浏览器会话)有助于均匀分配流量并降低速率限制或禁令的风险。
处理JavaScript密集型页面
由于Airbnb在客户端渲染大部分内容,静态HTML请求通常返回不完整的数据。Playwright或Selenium等工具允许你在无头浏览器中完全渲染页面,确保所有房源在提取前加载。结合智能等待逻辑(例如,等待某些元素出现)可进一步提高可靠性。
处理验证码和封锁
验证码是触发自动化流量检测的抓取工具的常见障碍。随机延迟、真实的浏览器指纹和基于会话的代理轮换都有助于最小化遇到它们的机会。如果确实出现验证码,最实用的解决方案是暂停执行以进行手动求解,或者在更高级的工作流程中,集成验证码求解服务。
使用API自动化大规模抓取
当你收集数千个房源或运行每日更新时,扩展手动维护的抓取工具变得效率低下。抓取API(例如Decodo的网络抓取API)自动化许多繁重的任务,如代理管理、渲染和重试。虽然这些服务带来额外成本和较少的灵活性,但它们非常适合持续监控或大规模市场情报项目。
保持抓取工具更新
Airbnb经常更新其网站设计和底层代码,这意味着即使是构建良好的抓取工具也可能在没有警告的情况下中断。保持抓取工具健康需要持续关注和主动的维护方法。
监控网站结构变化
小的前端调整(例如重命名类或更改容器层次结构)可能导致选择器停止工作。为了及早发现这些问题,安排定期测试运行并监控日志中的提取失败或缺失字段。当抓取工具返回空数据或格式错误的数据时设置轻量级警报可以帮助你在这些变化破坏工作流程之前检测到它们。
维护和更新代码
像对待任何其他软件项目一样对待抓取工具。记录每个部分的工作原理,保留代码的备份副本,并在Airbnb更改其HTML时更新选择器或解析逻辑。定期重构也是明智的:清理已弃用的代码、改进错误处理并确保与新版本的Playwright或Python的兼容性。在维护方面的小投资可以使抓取工具保持稳定并节省数小时的调试时间。
最后的思考
遵循本指南,你已学会如何使用Playwright和动态住宅代理设置功能性Python抓取工具。尽管具有挑战性,但抓取Airbnb对于它提供的关于房产趋势、定价策略和旅行者行为的宝贵见解来说非常值得。
如果你更喜欢简单性和可靠性而不是定制化,我们的网络抓取API可能是正确的选择。它消除了管理代理、浏览器和反机器人处理的需要,同时仍然提供对原始HTML或干净Markdown格式的Airbnb数据的完全访问。
关于作者

Dominykas Niaura
技术文案
Dominykas 在他的写作中独特地融合了哲学洞察力和专业技术知识。他的职业生涯始于电影评论家和音乐行业的文案,现在他是一位将复杂的代理和网络搜索概念变得通俗易懂的专家。
通过 LinkedIn 与 Dominykas 联系。
Decodo 博客上的所有信息均按原样提供,仅供参考。对于您使用 Decodo 博客上的任何信息或其中可能链接的任何第三方网站,我们不作任何陈述,也不承担任何责任。