如何使用 Python 对 Bing 搜索进行全量数据抓取
网络搜索是从网站中提取数据的艺术,它已成为开发人员、数据分析师和初创团队的首选工具。虽然谷歌最受关注,但对必应搜索结果进行刮擦也不失为一种明智之举,尤其是在了解地区情况或 SERP 饱和度较低的情况下。在本指南中,我们将向你展示如何使用 Python 和 Requests、Beautiful Soup 和 Playwright 等工具对 Bing 进行搜索。
Zilvinas Tamulis
最后更新: 6月 13日, 2025年
12 分钟阅读
为什么要搜索Bing搜索?
虽然Google经常占据中心位置,但Bing也有自己的优势,尤其是对于那些需要挖掘独特数据的人来说,必应值得一试。由于Bing的内容种类更丰富、搜索结果更简洁、区域相关性更强,因此搜索必应的搜索结果可以让您获得在其他地方可能会错过的洞察力。
Bing 的算法经常会出现与谷歌不同的页面,这在你考察竞争对手或试图寻找非主流内容时特别有用。例如,研究利基行业博客可能会在Bing上发现从未进入Google 前十名的瑰宝。
由于较少公司主动将Bing作为搜索引擎优化的目标,其结果也往往较少受到激进的关键字堆砌或内容农场的影响。这意味着您更有可能获得真正信息丰富的网页,而不是大量的点击诱饵和关联性文章。
最后一个好处是,Bing是微软设备上的默认搜索引擎,这使它在特定地区和企业环境中拥有更强的立足点。如果你要分析美国或企业受众的用户行为,Bing可能比Google更能让你一目了然。
简而言之,Bing 不仅仅是 “另一个 ”搜索引擎——它是一个有价值的数据源,具有独特的优势,尤其是当您要寻找新的视角、更清晰的结果或特定地区的见解时。
搜索Bing搜索结果的用例
既然我们已经介绍了Bing值得搜索的原因,那么让我们来看看如何才能真正利用这些数据。
对于搜索引擎优化极客来说,Bing提供了一个全新的角度来了解您或您客户的网站是如何出现在搜索结果中的。您可以监控关键字排名,跟踪随时间推移而发生的变化,并发现在Bing上表现良好而在Google上表现不佳的网页。
Bing搜索结果还有助于发现受众偏好、流行话题和内容差距。例如,准备推出产品的初创公司可以通过分析Bing搜索结果,了解用户正在提出哪些问题,以及哪些解决方案目前在该领域占据主导地位。
想知道谁在你的特定市场中获得了关注?通过Bing搜索,您可以轻松跟踪哪些竞争对手在特定关键字上排名靠前,或在搜索结果中占据重要位置。这有助于企业微调其信息传递,或发现其他企业错失的机会。
一言以蔽之,Bing搜索不仅仅是为了收集简单的数据,而是为了在优化、制定战略和扩展业务方面获得优势。
搜索Bing搜索的工具和方法
所以,你已经有了充分的理由和明确的使用案例——现在是时候谈谈工具了。根据你的目标、预算和技术诀窍水平,有几种刮擦Bing搜索结果的方法。下面列出了最常见的几种方法:
- 手动搜索。将搜索结果复制并粘贴到电子表格中可能适用于一次性研究,但很快就难以为继。这种方法速度慢、容易出错,而且对开发人员绝对不友好。对于演示来说非常好,但对于大规模数据来说就太糟糕了。
- Python(Requests + Beautiful Soup)。对于简单的 HTML 页面,Python 的 Requests 和 Beautiful Soup 库轻便实用。这种方法非常适合不需要 JavaScript 渲染的快速脚本,比如从基本结果页面抓取标题、URL 和片段。
- Playwright。 Playwright 可让你自动执行整个浏览器会话,因此非常适合抓取 JavaScript 较多的内容或动态内容。它非常适合更高级的用例,如提取丰富的片段或模拟跨页面的真实用户行为。
- API 和第三方抓取。如果你想节省时间(和一些麻烦),使用专用的刮擦 API 是明智的选择。例如,Decodo 的网络抓取 API 可以处理从旋转代理到解析 HTML 的所有事务,因此您可以专注于数据,而不是基础设施。
当大规模或频繁地对 Bing 进行刮擦时,使用代理是避免被阻止的关键。代理可以掩盖您的 IP 地址,并帮助将请求分发到多个位置,从而使必应更难检测到刮擦活动。轮换使用住宅或数据中心代理(如 Decodo 提供的代理)可以显著提高成功率,并保持您的刮擦活动顺畅无阻。
无论你是使用 Python 构建抓取,还是依赖第三方 API,提取Bing搜索数据的方法并不缺乏。只要确保选择与你的规模相匹配的方法——除非你喜欢 403 错误,否则不要跳过代理。
如何使用 Python 搜刮Bing搜索结果
设置环境
现在,您已经知道了为什么以及如何抓取 Bing 搜索结果,是时候设置您的 Python 环境了。我们将从 Requests 和 Beautiful Soup 开始,然后使用 Playwright 创建更多动态页面。下面是如何开始:
- 安装 Python。首先,确保计算机上安装了 Python 3.7 或更高版本。您可以从 Python 官方网站下载。要检查是否已安装,请运行:
2. 创建并激活虚拟环境(推荐)。使用虚拟环境隔离你的刮擦项目是个不错的做法,可以避免杂乱和库冲突:
3. 安装所需的库。您需要一些 Python 软件包才能开始使用:
4. 安装浏览器二进制文件。安装 Playwright 后,运行以下命令安装必要的浏览器二进制文件:
5. 测试设置。这里有一个简单的脚本来验证一切正常。该脚本使用 Requests 和 Beautiful Soup 来获取和解析必应的主页:
如果你在终端中看到类似 “Search - Microsoft Bing ”的标题,那么恭喜你,你已经准备好开始搜索了!接下来,我们将深入探讨如何实际提取搜索结果。
使用 Python 进行基本Bing搜索搜索
在深入研究浏览器自动化之前,让我们从最基本的开始--发出 HTTP 请求并解析 HTML 响应。这种方法非常适合 JavaScript 参与度不高的简单刮擦任务。我们将使用 Python 的 Requests 库获取页面,并使用 Beautiful Soup 提取数据。
请注意,如果Bing检测到自动访问,它可能会返回不同的 HTML 或完全阻止请求,因此这种方法最适合小规模测试,或与旋转用户代理标头和代理服务搭配使用。
要了解代理详情和凭证,请访问 Decodo 面板,购买适合您需要的计划,并获取用户名、密码和端点信息。
上述脚本的功能如下:
- 定义前提条件。代理凭证、用户代理标头、查询和目标 URL 都写在这里,随后将在脚本中使用。
- 发出请求。脚本通过代理服务发送 HTTP GET 请求和用户代理。这样可以确保请求不被检测到,并允许多次重复请求。
- 解析响应。请求抓取 HTML 页面后,Beautiful Soup 会对其进行分析,并解析所需的信息。在这里,它会找到所有带有 "b_algo "类的 <li> 元素,这是每个搜索结果所在的容器。
- 找到标题、URL 和描述。找到所有容器后,脚本会对其进行循环,并找到标题 (h2)、URL (href) 和描述 (p)。
- 打印结果。在循环中打印结果,然后重复该过程,直到找到搜索结果页面的所有结果。
重要提示:使用代理服务时,您的 IP 位置可能会影响必应的语言和区域设置。与 Google 不同的是,如果查询使用的是英语,但您的代理似乎来自法国或德国等地区,Bing 可能不会返回任何结果。要避免这种情况,可以选择:
- 使用通用搜索词(如品牌名称),
- 或在搜索请求中添加 setlang 和 cc(国家代码)参数,手动设置语言和地区:
Bing搜索的高级技术和常见挑战
随着Bing搜索设置的扩展,简单的 HTTP 请求和 HTML 解析很快就会受到限制。Bing 的搜索引擎结果页面包括动态元素、分页内容和僵尸检测机制,这使得仅使用 Requests 和 Beautiful Soup 进行大规模刮擦变得不可靠。这就是 Playwright 的用武之地,它提供了一个浏览器自动化层,其行为更接近真实用户。
以下是 Playwright 更适合搜索Bing的原因:
- JavaScript 渲染。必应使用 JavaScript 加载某些丰富的元素(如知识面板和新闻卡片)。Playwright 可以像真正的浏览器一样执行 JavaScript,让您可以抓取完整的渲染页面,而不仅仅是原始 HTML。
- 分页控制。与基本的搜刮不同,Playwright 允许您点击 "下一步 "按钮,并通过完整的浏览器上下文动态加载额外的搜索结果页面。
- 模拟人类行为。Playwright 支持键盘输入、滚动、鼠标移动和延迟,可让您的机器人模拟真实用户,帮助您避免被检测和封禁。
- 更好地避免验证码。虽然并非万无一失,但 Playwright 可以绕过必应的一些轻度反机器人措施,只需表现得更像浏览器而不是机器人即可。
- 截屏和调试功能。Playwright 可以捕捉截图,甚至录制刮擦会话的视频,从而更轻松地调试 DOM 中的变化或刮擦失败。
下面是一个 Playwright 脚本示例,它导航到 https://bing.com/,输入搜索查询,并抓取前 3 个结果页面。它还会截取每个页面的屏幕截图,这样你就可以看到页面在搜索过程中的样子,以及是否遇到任何问题:
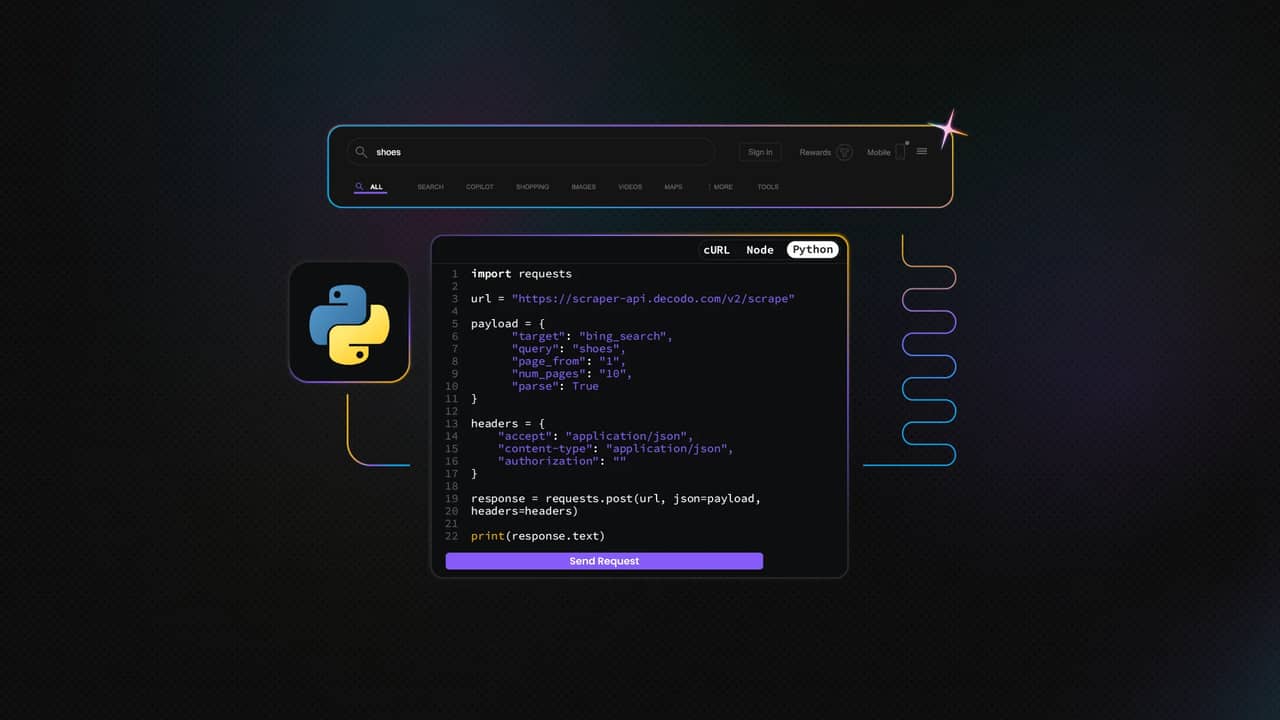
使用 API 搜索Bing
让我们面对现实吧——虽然我们刚刚创建的 Playwright 脚本可以完成工作,但它太长了,有点麻烦,而且绝对不是最适合初学者的。设置浏览器自动化、处理页面加载、导航分页、旋转代理服务、祈祷 Bing 不会在运行过程中抛出验证码...... 要做的事情太多了。老实说,即使是经验丰富的开发人员也不喜欢维护刮擦脚本,因为这些脚本可能会在一夜之间因为用户界面的微小变化而崩溃。
这就是搜索 API 的用武之地。与杂乱无章地使用库和调试选择器相比,scraping API 可以为你处理一切事务--HTTP 请求、JavaScript 渲染、代理轮换、绕过验证码等。当您需要扩展性、可靠性和快速迭代时,使用它们非常方便。
如果您正在寻找一个坚如磐石的解决方案,Decodo 的网络抓取 API 是一个不错的选择。它专为性能而设计,包括高级代理轮换、内置错误处理功能,并可与必应等主要目标一起使用。下面是一个使用 Python 的简单 API 请求:
你一定不会相信,API 的功能几乎与之前的长版 Playwright 脚本一模一样。它甚至配备了用户友好型 Web UI,只需点击几下,就能轻松配置和安排请求,并将结果导出为 JSON 或表格格式。
最后说明
使用 Python 对必应搜索结果进行抓取为我们带来了很多机会--从发现地区性洞察到在饱和度较低的搜索领域追踪竞争对手。有了 Python's Requests、Beautiful Soup、Playwright 和 Decodo's网络抓取 API 等工具,你就有了适合自己需求和规模的多种选择。请记住:如果你要频繁或大量地进行网络抓取,请不要忘记代理--它们是你在这次冒险中最好的朋友。试试这里介绍的方法,看看 Bing 有哪些 Google 隐藏的洞察力。
关于作者

Zilvinas Tamulis
Decodo 德口多专家专栏: 资深行业作家 Zilvinas Tamulis
作为一名拥有 4 年以上工作经验的技术作家,Žilvinas 将自己在多媒体和计算机设计方面的学习与创建用户手册、指南和技术文档方面的实际专业知识相结合。他的工作包括利用 JavaScript、PHP 和 Python 的实践经验,开发每天有数百人使用的网络项目。
通过 LinkedIn 与 Žilvinas 联系。
Decodo 博客上的所有信息均按原样提供,仅供参考。对于您使用 Decodo 博客上的任何信息或其中可能链接的任何第三方网站,我们不作任何陈述,也不承担任何责任。

