如何使用 Python 抓取网页表格: 从静态解析到动态提取完整指南
HTML表格是网站组织数据最常见的方式之一,包括财务报告、产品列表、体育比分、人口统计等。但这些数据被锁定在网页布局中。要使用它,您需要提取它。本指南将向您展示如何使用Python做到这一点,从简单的静态表格开始,逐步处理复杂的动态表格。
Justinas Tamasevicius
最后更新: 12月 08日, 2025年
9 分钟阅读

理解HTML表格
在抓取表格之前,您需要理解其结构。HTML使用标签来组织内容。要查看这一点,访问任何带有表格的网页,右键单击它,然后选择"检查"(如果需要帮助,请查看我们关于如何检查元素的指南)。
您只需要知道4个标签:
- <table> – 整个表格容器(想象成整个电子表格文件)
- <tr> – “表格行” – 单行(就像电子表格中的一行)
- <th> – “表格标题” – 标题单元格(列标题,如"名称"或"价格")
- <td> – “表格数据” – 数据单元格(单个值,如"$19.99")
表格是嵌套的。<table>包含<tr>(行),后者包含<th>(标题)和<td>(数据)。理解这种结构对于稍后选择正确的CSS或XPath选择器很重要。
前提条件
您需要安装Python以及几个库:
- Requests – 发送HTTP请求以下载网页
- BeautifulSoup4 – 将HTML解析为可搜索对象
- Pandas – 将抓取的数据组织成表格并导出为CSV/Excel
- lxml – pandas.read_html需要的快速解析器
- Selenium – 为JavaScript密集型网站自动化浏览器
要安装所有这些库,打开终端(或命令提示符)并运行以下命令:
我们将使用requests和BeautifulSoup处理静态网站,当您需要抓取动态内容时使用Selenium。
如何抓取静态HTML表格
静态表格在初始HTML中包含所有数据,不需要JavaScript加载。有两种方法可以抓取它们。
方法1. 最简单的方法(pandas.read_html)
对于简单的静态表格,pandas有一个完成繁重工作的函数: read_html()。
此函数扫描HTML,找到所有<table>标签,并将它们转换为pandas DataFrames列表。
运行脚本时,控制台输出如下所示:

方法2. 手动方法(BeautifulSoup)
有时pandas.read_html会失败,或者您需要更多控制。这是使用BeautifulSoup的手动方法。
我们将在5个清晰的步骤中抓取相同的Wikipedia页面。
步骤1. 获取网页
使用requests下载页面的HTML。
步骤2. 使用BeautifulSoup解析HTML
将原始HTML传递给BeautifulSoup以创建可搜索对象。
步骤3. 定位并提取表格
在浏览器中右键单击表格并选择"检查"。您会看到它有一个class属性"wikitable"。
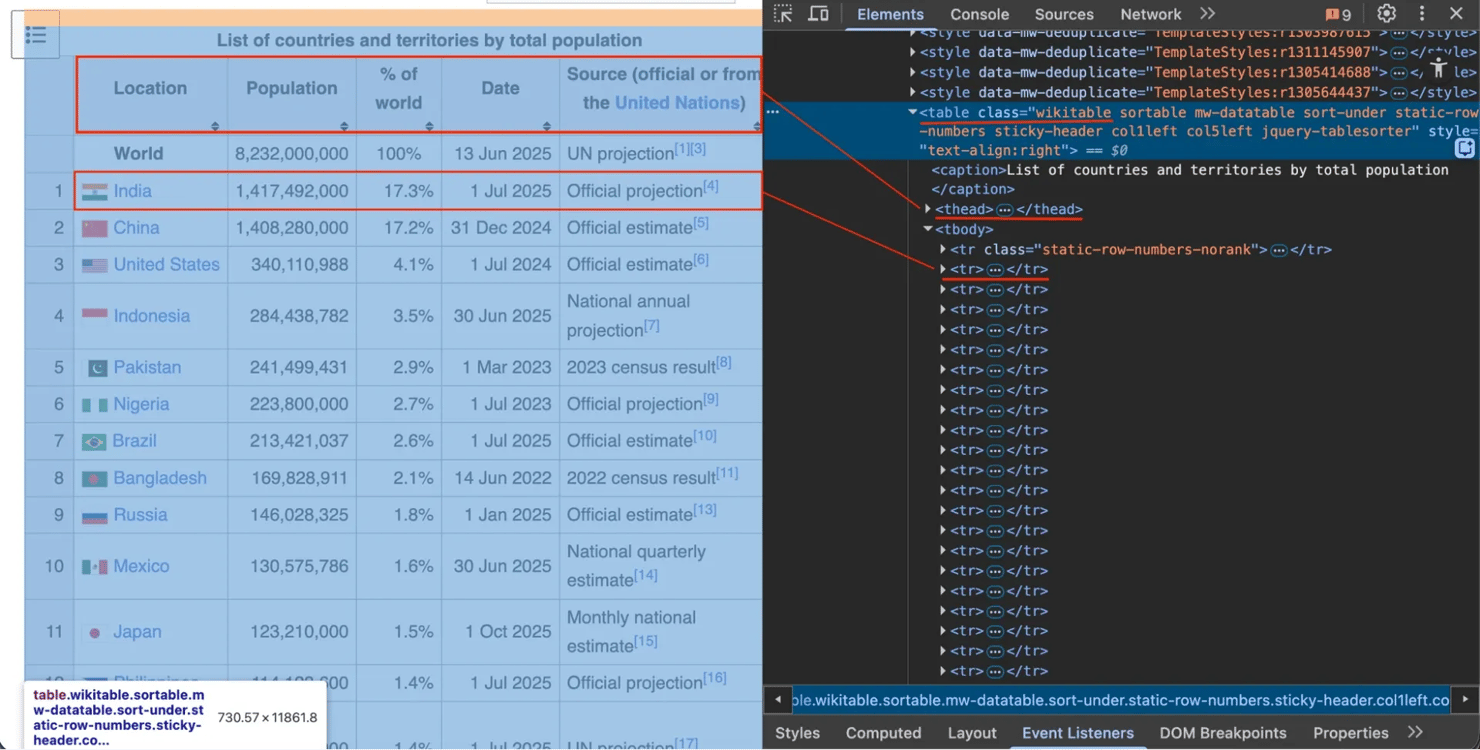
使用此类查找表格,然后提取所有标题(<th>)和行(<tr>)。
步骤4. 将数据转换为pandas DataFrame
将您的列表转换为结构化DataFrame。
pandas DataFrame是一个强大的内存中表格,类似于电子表格。虽然我们的all_rows变量只是一个Python列表的列表,但将其转换为DataFrame允许我们轻松地使用标题标记数据、清理数据、分析数据,最重要的是,使用单个命令将其导出为CSV或Excel等格式。
步骤5. 保存数据
将DataFrame导出为CSV。
最终的CSV文件将如下所示:
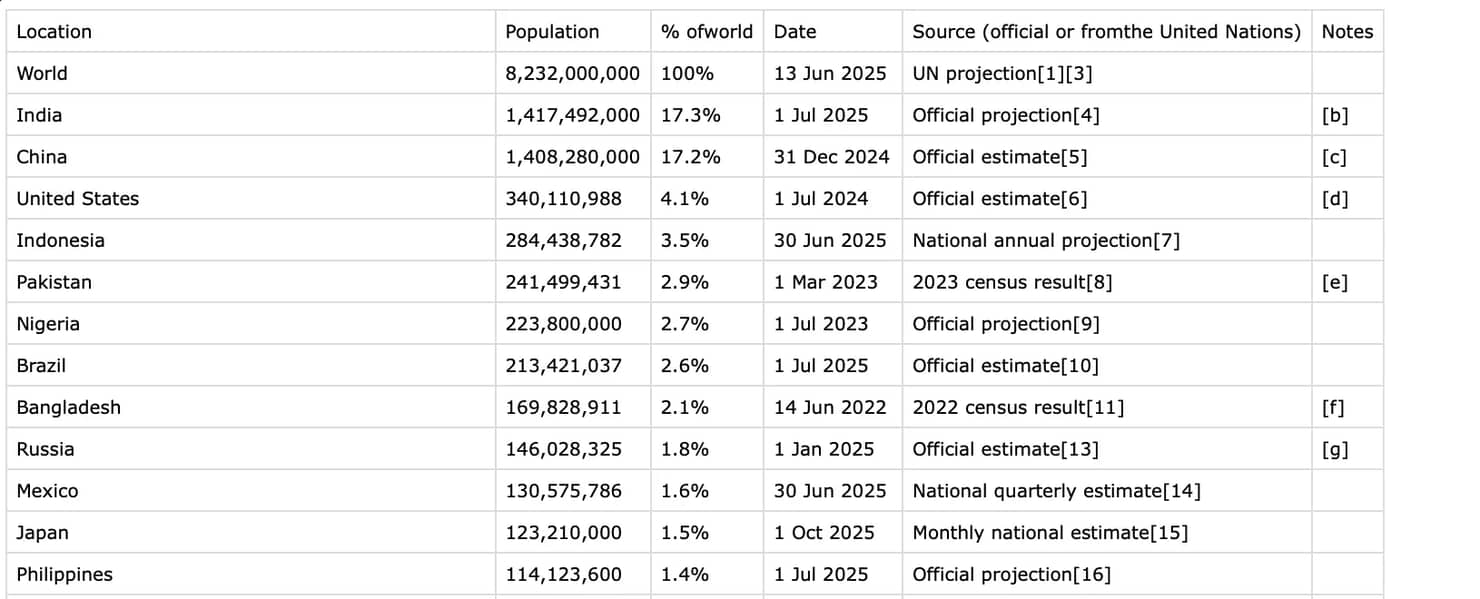
此方法使用了Python网页抓取的所有基本原理,并为您提供完全控制。您可以进一步修改代码以仅提取特定行或列,或筛选相关数据。
快速提示 – 始终首先尝试方法1。它快速简单。如果失败或您需要更多控制,请使用方法2。
处理复杂的表格结构(colspan和rowspan)
某些表格使用colspan(跨越多列)或rowspan(跨越多行)合并单元格。
问题 – 简单的循环会将数据放在错误的列中。
修复方法 – 首先尝试pandas.read_html。它通常足够智能,可以自动正确解析带有colspan和rowspan的表格。
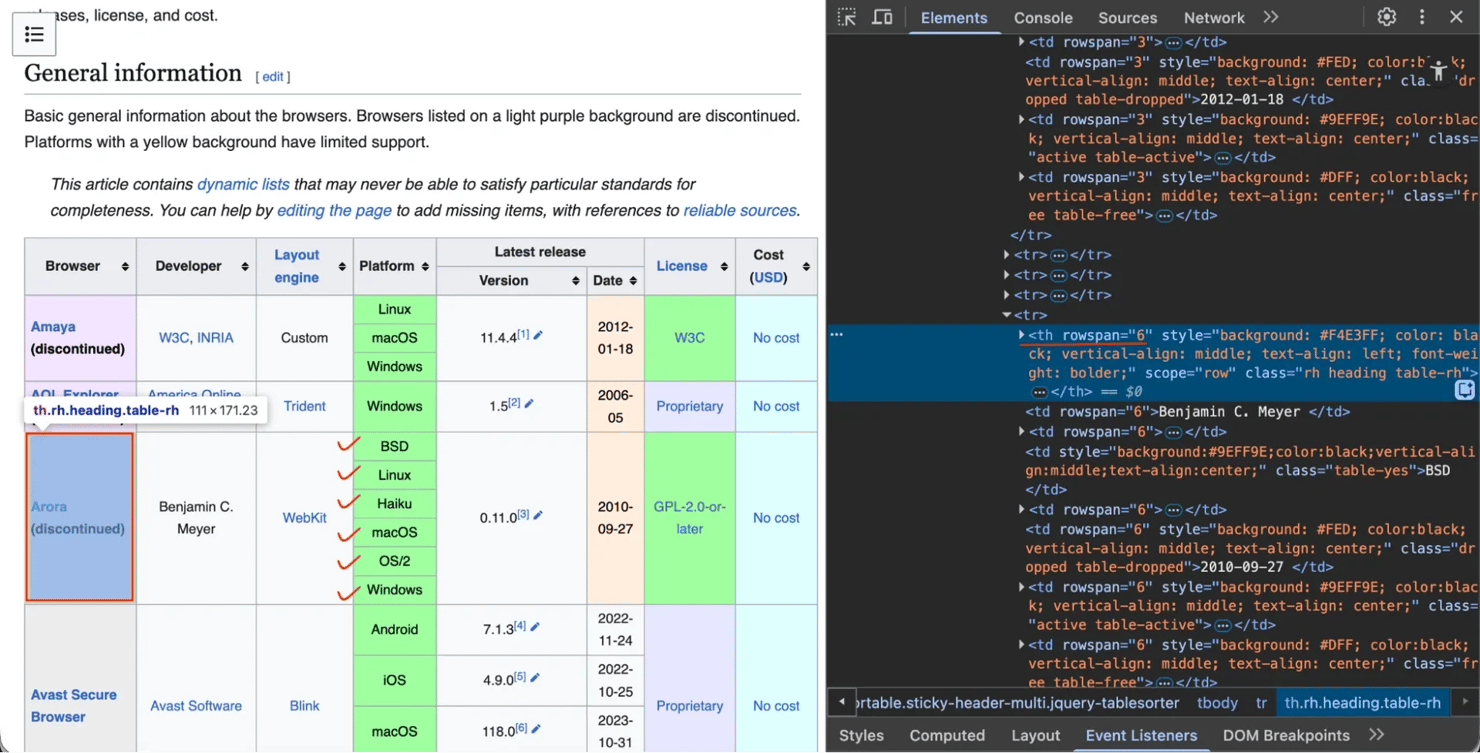
让我们以网页浏览器比较页面为例。提到"Arora"浏览器的行使用rowspan跨越6行。
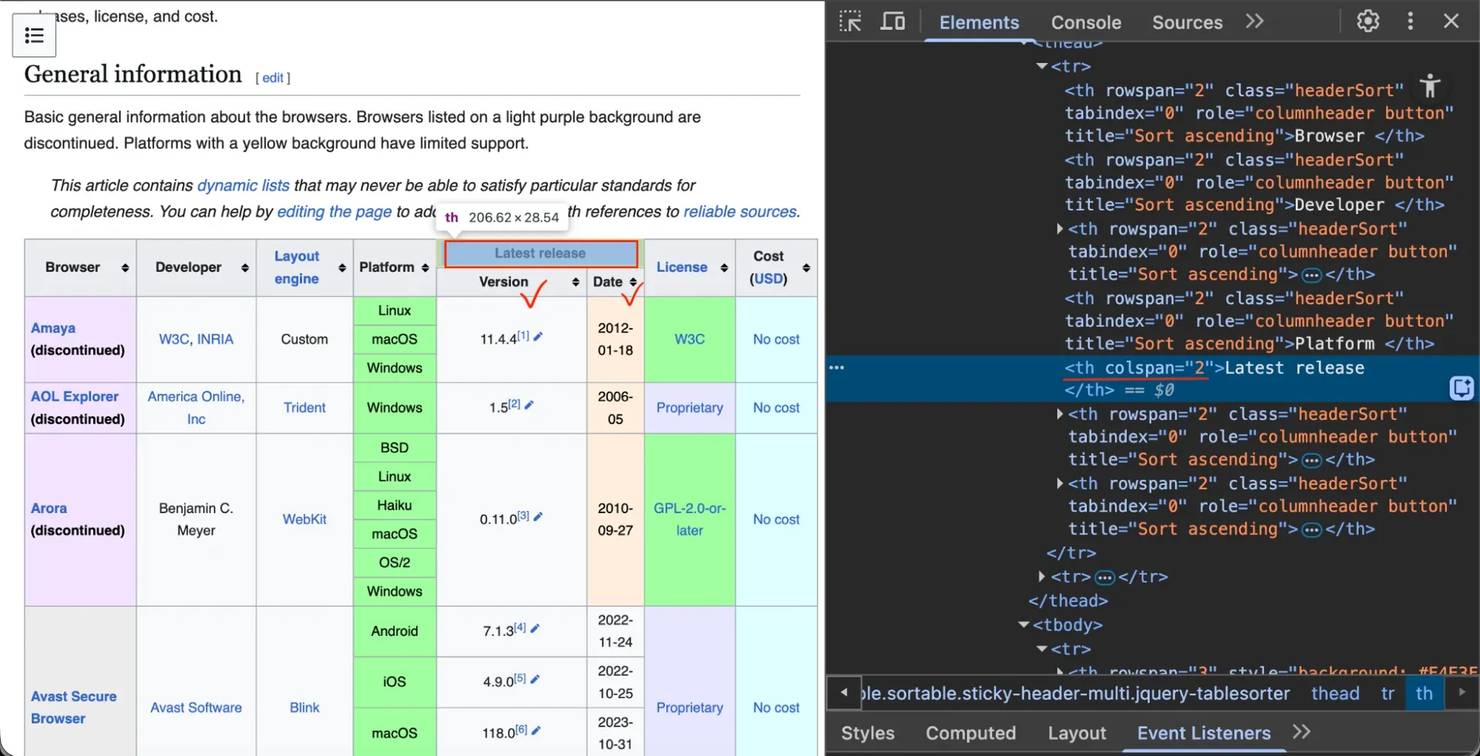
"Latest release"标题使用colspan跨越2列(“Version"和"Date”)。
让我们看看pandas是否可以处理它。
然后您将获得成功扁平化复杂标题和行的CSV。
当pandas.read_html(方法1)在复杂表格上失败时,您可以使用专门的库,如html-table-extractor。其主要目的是正确解析复杂表格,自动扩展合并的单元格以构建干净的矩形数据网格。
首先,您需要安装它:
以下是结合BeautifulSoup查找表格和html-table-extractor解析表格的代码:
清理和保存数据
原始抓取的数据通常很混乱。例如,在我们在方法2(BeautifulSoup)中创建的DataFrame中,Population列包含字符串,如"1,417,492,000"。因为这是一个字符串而不是数字,所以您无法使用它进行计算。让我们清理它。
您可以将以下行添加到方法2脚本中以清理数据。此代码直接从您之前创建的df变量继续:
清理后,保存您的数据。有关更多格式(JSON、数据库等),请查看我们关于如何保存抓取数据的指南。
如何抓取动态(JavaScript)表格
您运行抓取器,但表格数据为空。您检查HTML,看到"Loading…"或空的<div>。发生这种情况是因为网站使用JavaScript动态加载数据。requests.get()仅检索初始HTML,它不执行JavaScript。如果表格数据在页面渲染后加载,您的抓取器将看不到它。
解决方案#1. 查找隐藏的API
许多网站通过后台API请求加载数据。您可以拦截此API并直接请求数据:
- 在浏览器中打开开发者工具(F12)
- 转到Network选项卡 – 按Fetch/XHR筛选
- 重新加载页面
- 查找返回JSON数据的请求(这是您的表格内容)
像Yahoo Finance和Google Finance这样的金融网站通常使用这种模式。在下图中,您可以看到Fetch/XHR选项卡捕获返回干净JSON数据的请求。
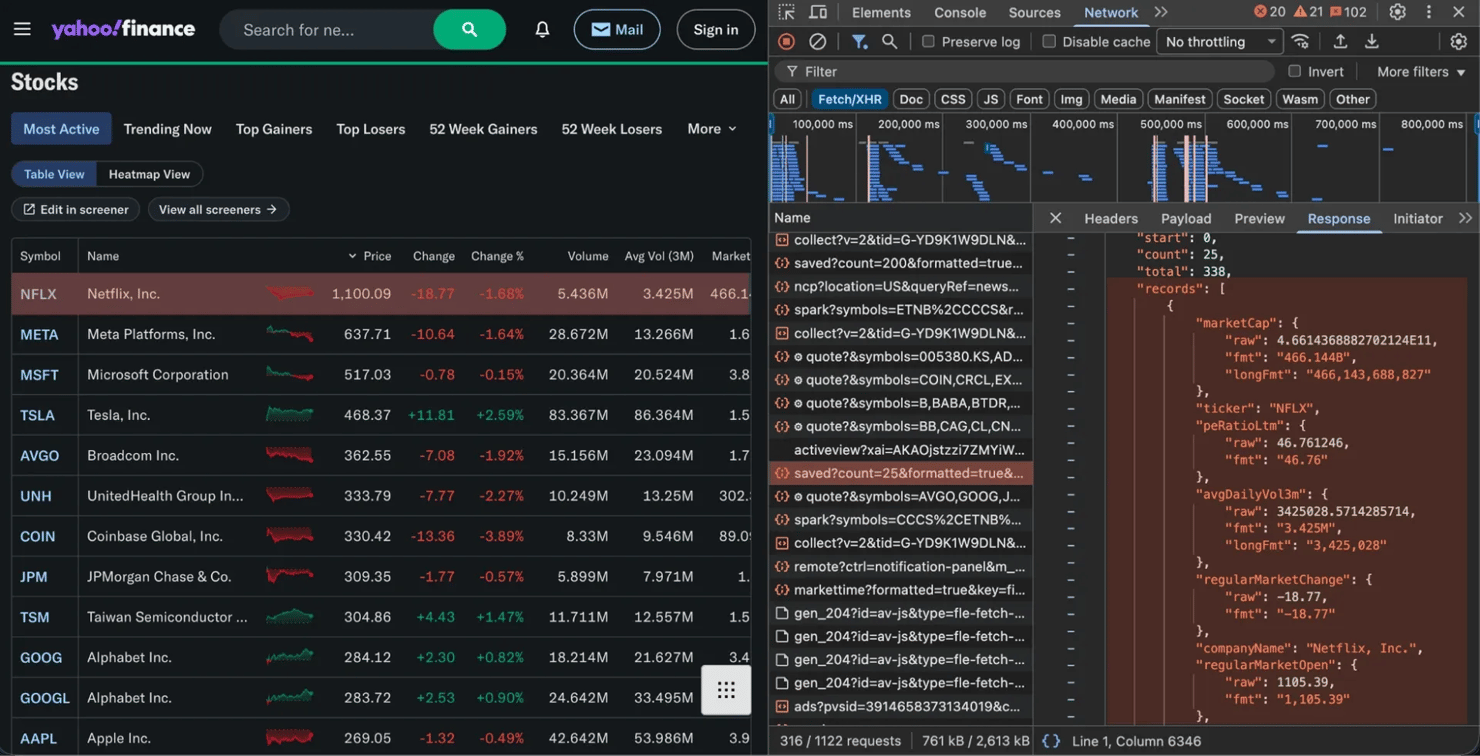
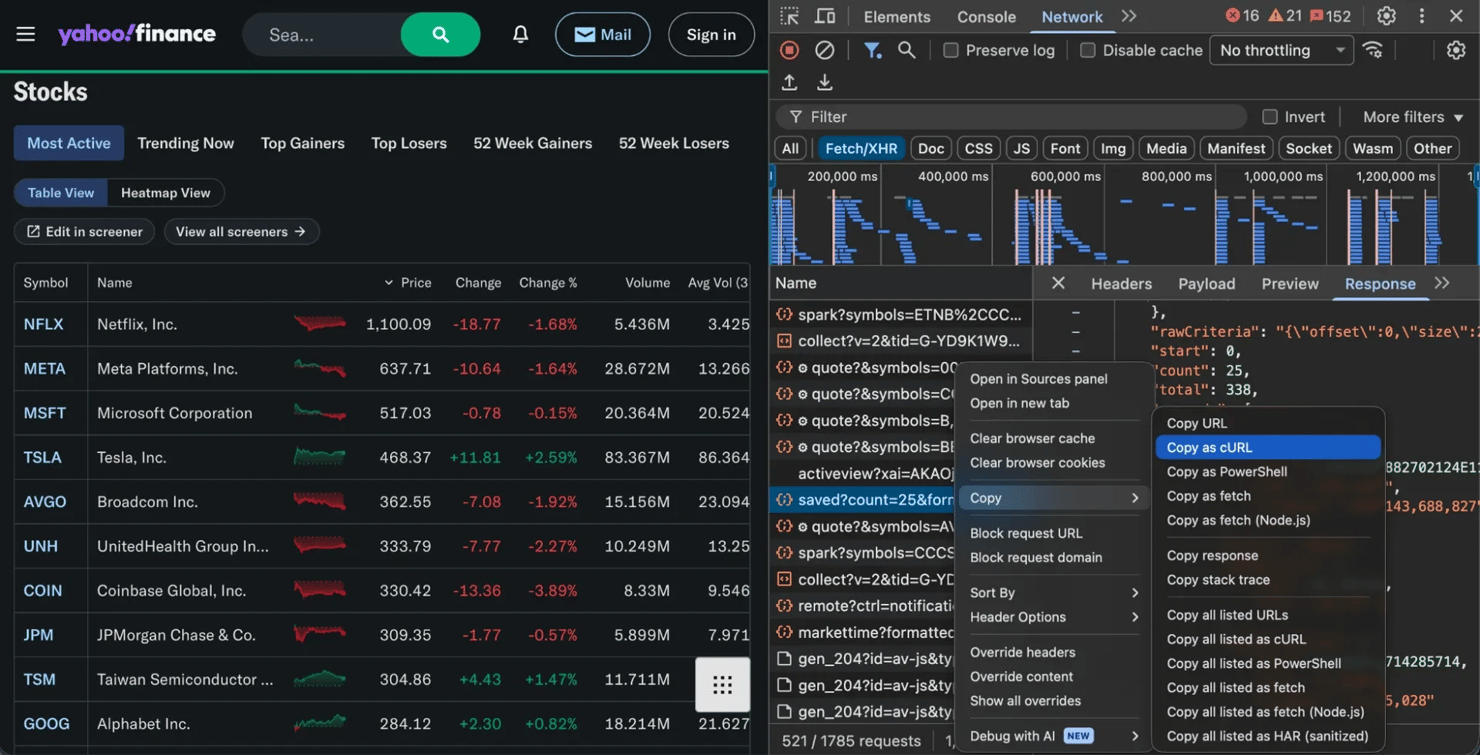
找到正确的请求后,右键单击它并选择Copy as cURL(或记下URL、标头和参数)。然后,您可以在Python中重新创建该请求。
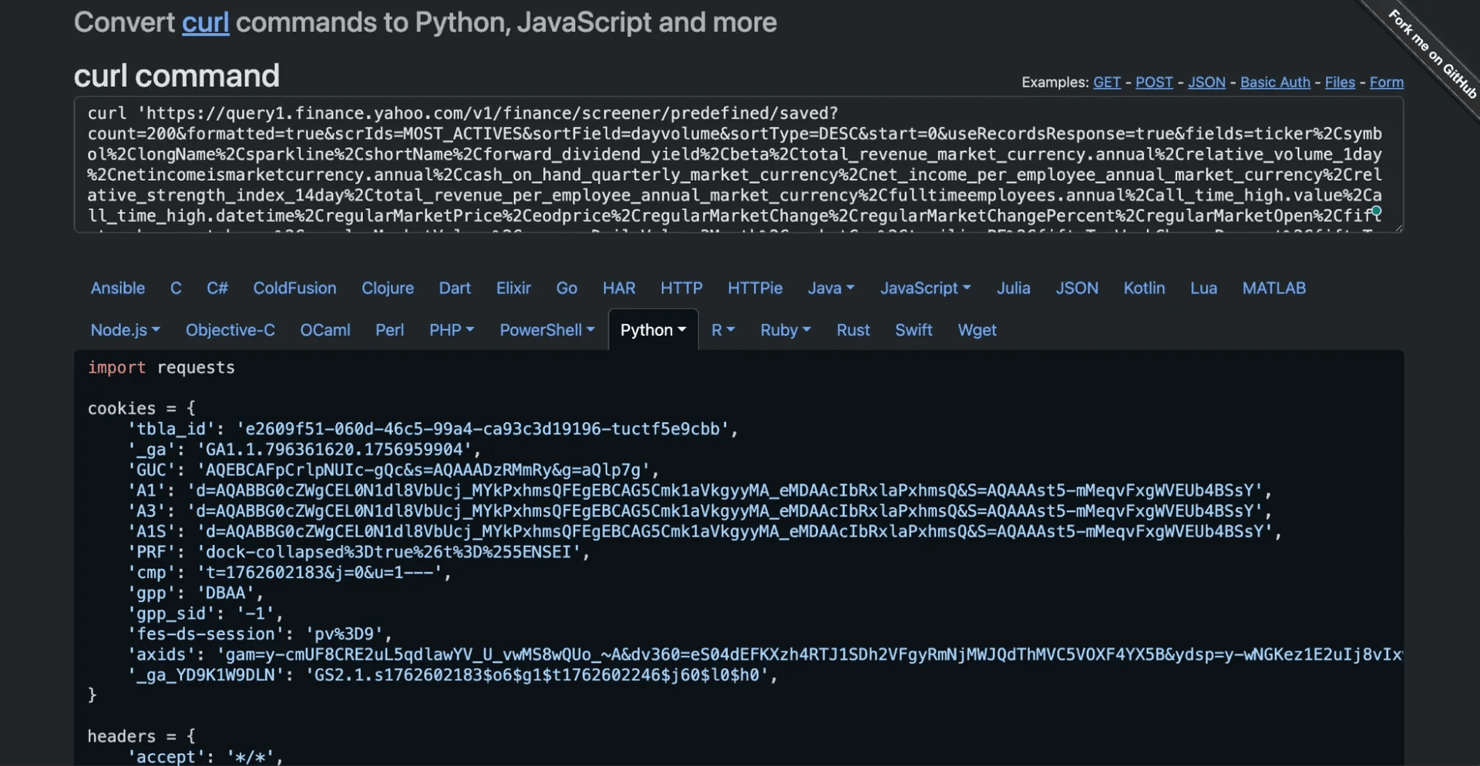
将"Copy as cURL"命令转换为Python的专业提示是使用在线工具,如curl转换器。您可以粘贴整个cURL命令,它将自动使用requests库生成等效代码。
运行此代码将打印干净的JSON数据,看起来像这样:
重要说明: 如果您的请求失败或没有获得数据,网站可能正在阻止您的脚本。要解决此问题,您需要使您的请求看起来更像真实用户。我们在本指南后面的最佳实践和道德考虑部分中介绍了这些技术。
解决方案#2. 使用无头浏览器
如果没有API可以定位,您需要自动化真实浏览器来渲染JavaScript。在服务器上运行时,这称为无头浏览器。像Selenium这样的工具将:
- 打开真实浏览器(如Chrome)
- 等待JavaScript执行和表格加载
- 为您提供最终渲染的HTML进行解析
这也是处理动态分页的唯一方法,即当您需要单击触发JavaScript的Next按钮时。我们将在下一节中介绍这一点。
这种方法比直接API请求更慢且资源更密集,因此始终首先检查隐藏的API。
如何抓取分页表格
表格通常分布在多个页面上(“第1页”、"第2页"等)。关键是弄清楚"Next"按钮的工作原理。
情况#1. 静态分页
要查找的内容 – 单击"Next"并检查URL是否更改(例如,更改为/?page=2)。如果是,您正在处理静态网站。
解决方案 – 在循环中使用requests。以CoinMarketCap为例。它使用像/?page=2、/?page=3这样的URL。如果您检查"Next"按钮,您会看到它只是一个简单的链接(<a>标签),具有静态href属性。
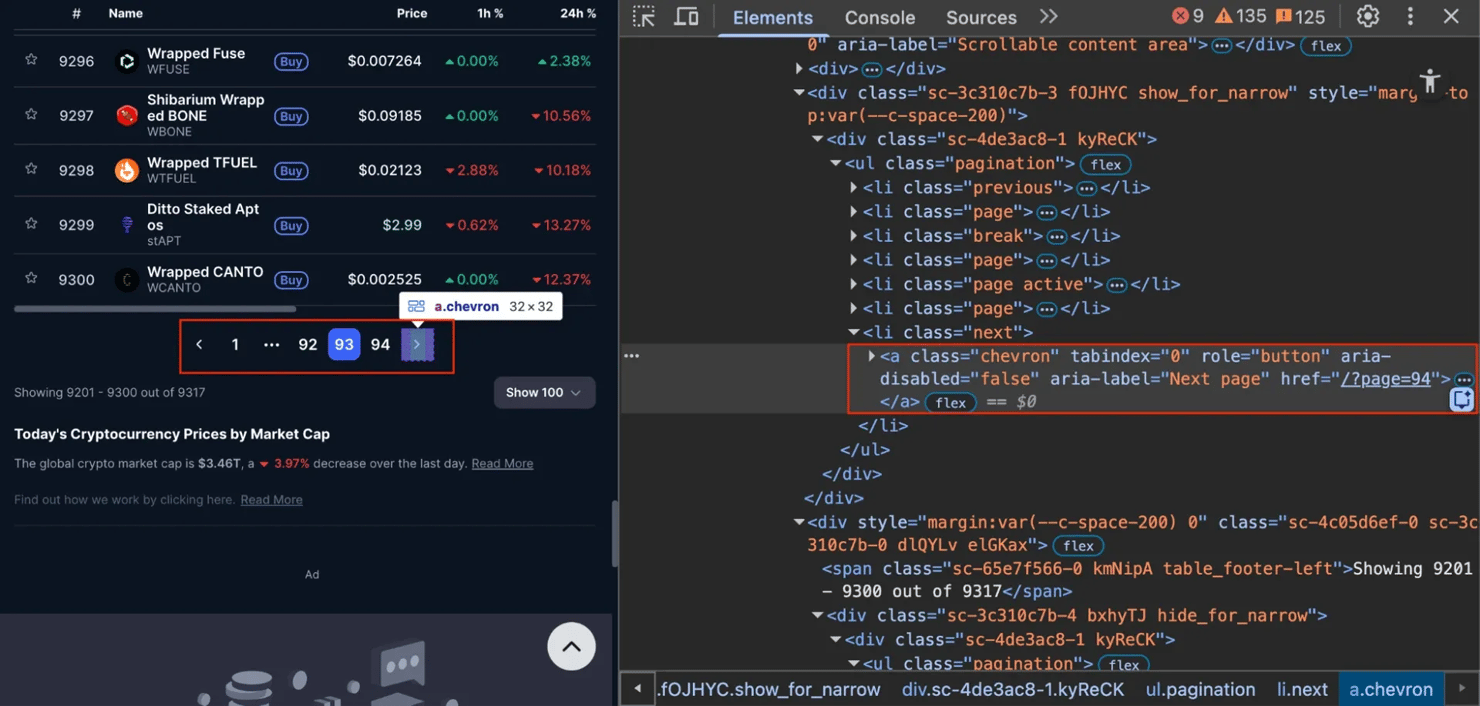
因为URL简单且可预测,您可以使用requests和pandas循环抓取它:
情况#2. 动态分页
要查找的内容 – 单击"Next"并检查URL是否保持不变,但表格内容发生变化。这意味着网站使用动态分页。
解决方案 – 使用无头浏览器,如Selenium模拟单击"Next"按钮。
让我们以Datatables为例进行抓取。此页面使用JavaScript加载其数据和分页。
这种相同的逻辑可以使用其他现代工具(如Playwright进行网页抓取)应用。
现代方法. 人工智能(AI)可以抓取表格吗?
这是当今最常见的问题,简短的答案是"可以,但有注意事项"。
人工智能(AI)作为助手
人工智能(AI)聊天机器人非常适合生成代码。复制表格的HTML,粘贴到ChatGPT或Claude中,并要求它编写BeautifulSoup脚本。您将在几秒钟内获得可用代码,而不是手动编写它。您可以在我们的其他指南中了解有关使用ChatGPT进行网页抓取或Claude进行网页抓取的更多信息。
但聊天机器人有局限性。它们编写代码,但不为您运行代码。它们无法渲染JavaScript、管理代理或处理被阻止。当网站更改其HTML(这种情况经常发生)时,代码就会崩溃。
人工智能(AI)作为抓取器本身
真正的人工智能(AI)抓取解决方案不仅生成代码,它理解页面结构并适应变化。您不必编写脆弱的CSS选择器,如soup.find(class_="wikitable"),而是用简单的英语告诉它您想要什么数据。
这就是Decodo的人工智能(AI)Parser所做的。它是最好的人工智能(AI)数据收集工具之一,因为当网站发生变化时它保持弹性。有关此方法的更多信息,请参阅Decodo如何处理人工智能(AI)数据收集。
最佳实践和道德考虑
抓取很强大,但您需要尊重他人。每秒向服务器发送数百个请求会很快被阻止。以下是如何负责任地抓取(并避免被禁止):
- 首先检查robots.txt. 大多数网站在website.com/robots.txt处都有一个文件,说明机器人的规则。我们有关于如何检查网站是否允许抓取的完整指南
- 尊重服务条款(ToS). ToS是一份法律文件。查看它以确保您没有违反政策,特别是对于商业用途。
- 使用代理网络. 您的家庭IP地址是网站的明显标志。在10或100个请求后,您将被阻止。代理,尤其是来自动态住宅代理网络的代理,通过不同的真实设备路由您的请求,每次都使您看起来像一个普通的独特用户。这是大规模可靠抓取的关键
- 使用User-Agent. 如我们的示例所示,User-Agent字符串使您的请求看起来像来自浏览器,而不是脚本。这绕过了许多基本的反机器人系统
- 在请求之间添加延迟. 在循环内添加time.sleep(2)。这对服务器是礼貌的,使您看起来不像机器人。(您甚至可以构建Python requests retry系统来自动处理此问题。)
常见问题排查
最常见的错误是AttributeError: 'NoneType' object has no attribute 'find'。这可能是最常见的抓取错误。这意味着您试图在None上调用方法,当您的选择器找不到任何内容时会发生这种情况。
修复方法 – 检查崩溃前的行。您的soup.find()返回None,因为它没有匹配任何内容。仔细检查您的选择器是否有拼写错误,或检查实际HTML以查看类名真正是什么。
其他常见问题
以下是一些常见的抓取错误和修复方法:
- 404 Not Found. 您的URL错误,或页面不存在。检查拼写错误
- 403 Forbidden. 服务器正在阻止您。添加User-Agent标头以使其看起来像浏览器。如果这不起作用,您需要代理来隐藏您的身份
- 429 Too Many Requests. 您抓取得太快。在请求之间添加time.sleep(2)以减慢速度。如果您仍然被阻止,请使用代理网络来轮换您的IP地址
空数据/缺少内容. 数据可能是用JavaScript加载的。使用浏览器的Network选项卡找到隐藏的API端点,或切换到无头浏览器自动化工具以等待页面完全加载
总结
您已经学会了如何在Python中抓取表格,从简单的pandas一行代码到复杂的Selenium设置。这些工具非常适合小型项目和学习。
但抓取器很脆弱,网站经常更改其HTML。扩展到数千页意味着处理代理、无头浏览器和验证码。如果这听起来很繁琐,还有另一种选择。
您可以使用Decodo网页抓取API,而不是自己构建和维护抓取器。发送URL,API处理混乱的事情(代理、JavaScript渲染、反机器人措施),您将得到干净的JSON。
此外,如果您正在构建人工智能(AI)代理或自动化工作流,您可以与LangChain和n8n集成。
关于作者

Justinas Tamasevicius
Decodo 德口多专家专栏: 工程主管 Justinas Tamasevicius
Justinas Tamaševičius 是工程主管,在软件开发领域拥有二十多年的专业经验。从学生时代自学成才的激情开始,他的职业生涯跨越了后端工程、系统架构和基础架构开发等领域。
Justinas 目前负责领导工程部门,推动创新,提供高性能的解决方案,同时保持对效率和质量的高度关注。
通过 LinkedIn 与 Justinas 联系。
Decodo 博客上的所有信息均按原样提供,仅供参考。对于您使用 Decodo 博客上的任何信息或其中可能链接的任何第三方网站,我们不作任何陈述,也不承担任何责任。


