如何使用 Python 爬取 Google Scholar 学术文献信息
Google Scholar是一个免费的学术文章、书籍和研究论文搜索引擎。如果你正在为研究、分析或应用程序开发收集学术数据,这篇博客文章将为你提供可靠的基础。在本指南中,您将学习如何使用Python抓取Google Scholar,设置代理以避免IP禁令,构建一个可用的抓取器,并探索扩展数据收集的高级技巧。
Dominykas Niaura
最后更新: 5月 30日, 2025年
10 分钟阅读
为什么要抓取Google Scholar
网络抓取Google Scholar可以解锁难以手动收集的数据点。从书目数据库到研究趋势分析,用户可能希望自动化这一过程的原因数不胜数。
通过抓取Google Scholar,您可以提取有价值的元数据,如文章标题、摘要、作者和引用计数。这对于创建数据集、构建学术工具或跟踪特定领域内的影响和趋势特别有用。
您还可以提取合著者数据和“引用者”信息,以分析协作网络或学术影响。您可以使用Google Scholar引用数据进行引文分析,提取完整的作者资料进行研究分析,或捕获Google Scholar的有机结果进行比较研究。
Google Scholar 抓取需要什么
在开始抓取Google Scholar之前,确保你有正确的设置是很重要的。以下是您需要的内容:
- 已安装Python 3.7或更高版本。Python的灵活性和庞大的库生态系统使其成为网络抓取的首选语言。请确保您的计算机上安装了Python 3.7或更高版本。你可以从官方网站下载。
- 请求和BeautifulSoup4库。您需要两个Python库来发送web请求和解析HTML内容。Requests允许您以编程方式发出HTTP请求,而BeautifulSoup4则使您可以轻松地从HTML文档中导航和提取数据。您可以在终端中使用以下命令安装它们:
- 基本熟悉浏览器检查工具。您应该知道如何使用检查元素功能(在Chrome、Firefox、Edge和其他浏览器中可用)。检查页面元素可以帮助您识别抓取器需要查找和提取正确数据的HTML结构、类和标签。
- 可靠的代理服务。Google Scholar积极限制自动访问。如果你抓取的不仅仅是几个页面,那么代理服务至关重要。使用住宅或轮换代理可以帮助您避免IP禁令,并保持稳定的抓取会话。对于小规模的手动测试,代理可能不是必需的,但对于任何严重的刮擦,它们都是必备的。
为什么代理对于稳定的抓取是必要的
在抓取Google Scholar时,代理非常有用。Google Scholar具有强大的反机器人机制,如果检测到异常行为,例如在短时间内发送太多请求,可以快速阻止您的IP地址。通过将流量路由到不同的IP地址,代理可以帮助您分发请求,避免达到速率限制或触发验证码。
为了获得最佳效果,建议使用动态住宅代理。住宅IP与真实的互联网服务提供商相关联,使您的流量看起来更像是在家浏览的典型用户。理想情况下,使用轮换代理服务,为每个请求自动分配一个新的IP地址,提供最大的覆盖范围并最大限度地减少被禁止的机会。
在Decodo,我们提供住宅代理,成功率高(99.92%),响应时间快(<0.6秒),地理定位选项广泛(全球195多个地点)。以下是获取计划和代理凭据的简单方法:
- 前往Decodo仪表板并创建一个帐户。
- 在左侧面板上,单击住宅和住宅。
- 选择订阅、Pay As You Go 计划,或选择3天免费试用。
- 在代理设置选项卡中,根据需要选择位置、会话类型和协议。
- 复制您的代理地址、端口、用户名和密码以供以后使用。或者,您可以单击表右下角的下载图标下载代理端点(默认为10)。
一步一步谷歌学者抓取教程
让我们一步一步地浏览一下抓取Google Scholar的完整Python脚本。我们将分解代码的每个部分,解释为什么需要它,并向您展示如何将它们组合在一起以创建一个可靠的scraper。
1.导入所需的库
我们首先导入必要的库:用于发出HTTP请求的请求和来自bs4模块的用于解析HTML的BeautifulSoup。使用这些库,您可以像浏览器一样发送HTTP请求,然后解析生成的HTML以准确提取所需内容:
2.设置代理
在脚本的顶部,我们定义代理凭据并构建代理字符串。此字符串稍后用于配置我们的HTTP请求,使其通过代理传输。在这个例子中,我们将使用一个代理端点来随机化位置,并在每次请求时轮换IP。请确保在适当的位置插入您的用户名和密码凭据:
3. 定义自定义标头和代理
通过使用详细的用户代理字符串,我们确保服务器将请求视为任何常规浏览器请求。这有助于避免自动脚本可能导致的阻塞。当没有提供代理URL时,我们没有将代理设置为None,而是使用空字典,简化了请求逻辑,使代理参数始终收到字典。
4. 检索并验证页面
以下代码块将我们的HTTP GET请求发送到Google Scholar。通过传递头文件dict,我们将自己呈现为一个真正的浏览器,并在配置代理时透明地路由代理。之后,我们立即检查响应的状态代码。如果不是“200 OK”,我们会打印一个错误并返回一个空列表,以防止进一步解析不完整或有错误的页面。
5.解析HTML内容
成功下载页面后,我们使用BeautifulSoup解析其内容。然后,解析器使用类“gs_r”搜索所有<div>元素,该类通常封装每个Google Scholar结果。
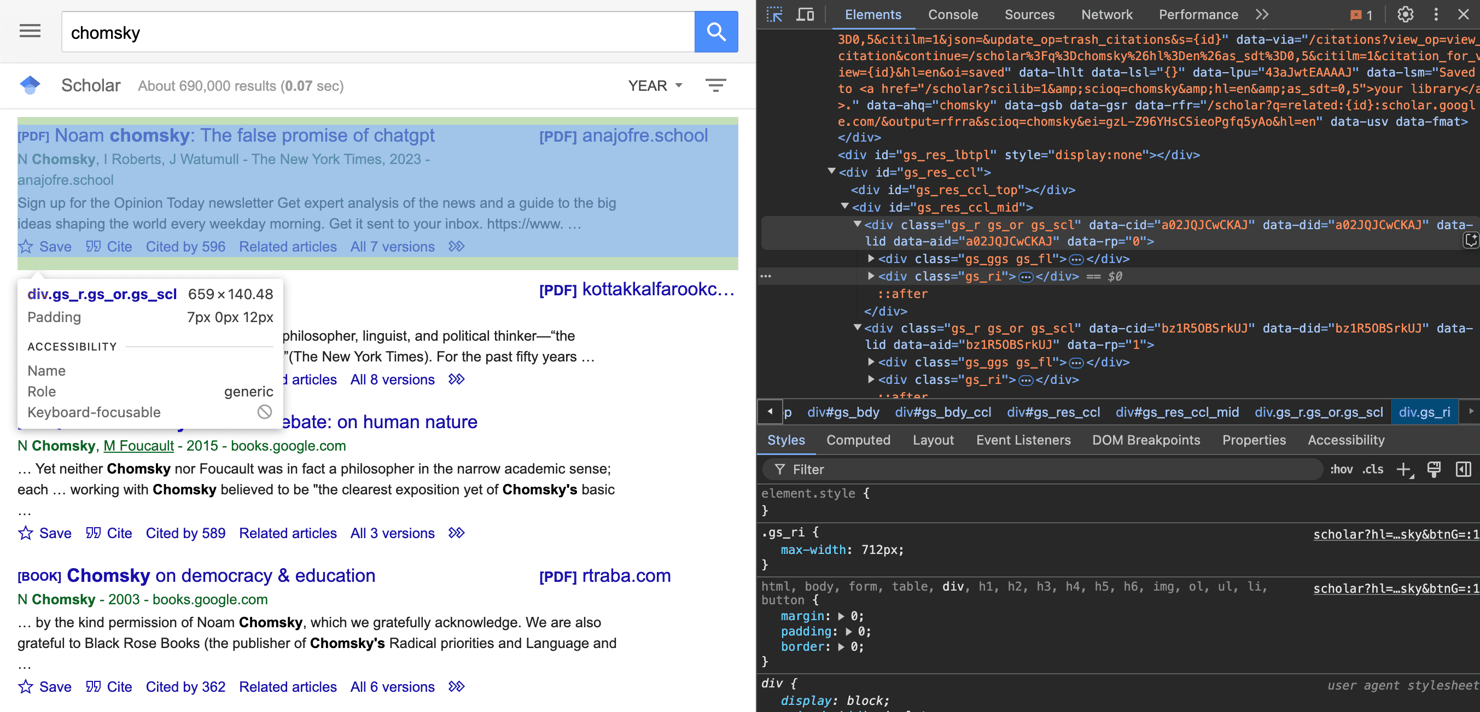
我们使用浏览器的Inspect工具发现了这个类:通过单击Google Scholar结果框,开发人员工具会突出显示相应的<div>及其类。
6. 从每个结果中提取数据
接下来,我们遍历刚刚选择的每个结果块,提取我们关心的字段,如标题、作者、摘录和引用信息,跳过任何非真实出版物(如作者简介摘要)。
下面是上面代码的作用:
- 标题提取和过滤。我们在每个结果中寻找一个<h3 class=“gs_rt”>。如果它丢失了,我们完全跳过那个块。我们也会忽略标题以“的用户资料”开头的任何结果,因为这是Google Scholar的作者概述部分,而不是出版物。
- 作者和出版信息。接下来,我们抓取<div class=“gs_a”>中的任何文本。这通常包含作者姓名、期刊标题和出版日期。如果它不存在,我们记录为“无”。
- 说明。该代码段位于<div class=“gs_rs”>中。这是Google Scholar在每个标题下显示的简短摘录。同样,如果它缺失,我们指定None。
- 引用次数和链接。我们搜索文本以“Cited by”开头的<a>标签。如果找到,我们解析下一个整数。我们还将其href属性(相对URL)作为前缀“https://scholar.google.com创建引用论文列表的完整链接。如果没有找到“引用者”链接,我们将计数和链接设置为合理的默认值。
- 保存记录。最后,每个条目词典(现在包含标题、作者、摘录、引用计数和链接)都附加到我们的数据列表中以供以后使用。
分页和循环
要收集第一页以外的结果,我们需要处理Google Scholar的分页。创建一个函数并将其命名为scrap_multiple_pages。它将通过迭代每个页面的开始参数,重复调用我们的单页抓取器,并将所有单个页面结果拼接到一个合并列表中,从而自动分页:
- 初始化一个空列表。我们从all_data=[]开始收集所有页面的每个结果。
- 循环页码。for i in range(num_pages)循环每页运行一次。所以,i=0是第一页,i=1是第二页,以此类推。
- 构造正确的URL。在第一次迭代(i==0)中,我们使用原始的base_URL。在后续迭代中,我们在URL后附加start={i*10}。Google Scholar需要一个跳过前N个结果的start参数(每页10个)。我们选择&还是?这取决于baseurl是否已经具有查询参数。
- 刮掉每一页。我们调用scrape_google_scholar(page_url,proxy_url)来获取和解析该页面的结果。
- 如果没有结果,就早点停下来。如果一个页面返回一个空列表,我们假设没有什么可以抓取和打破循环的了。
- 汇总所有结果。每个页面的page_data都扩展到all_data上,因此在循环结束时,您有一个包含所有请求页面的每个结果的列表。
运行脚本
在最后一节中,我们设置了搜索URL和页面计数,调用scraper(具有代理支持),然后循环返回的项目以打印每个项目。运行脚本时,此块:
- 初始化查询。使用您的学者搜索参数定义base_url。设置num_pages以控制要获取的结果页的数量。
- 启动刮刀。调用scrape_multiple_pages(base_url,num_pages,proxy_url=proxy),它在幕后处理分页和代理路由。
- 格式化和输出结果。遍历结果列表中的每个字典。以可读的布局打印标题、作者、描述、“引用者”计数和完整的引用链接。
最后一个块确保在执行时,脚本通过您的代理无缝连接,在指定数量的页面上获取和解析Google Scholar结果,并以有组织、人性化的格式显示每条记录。
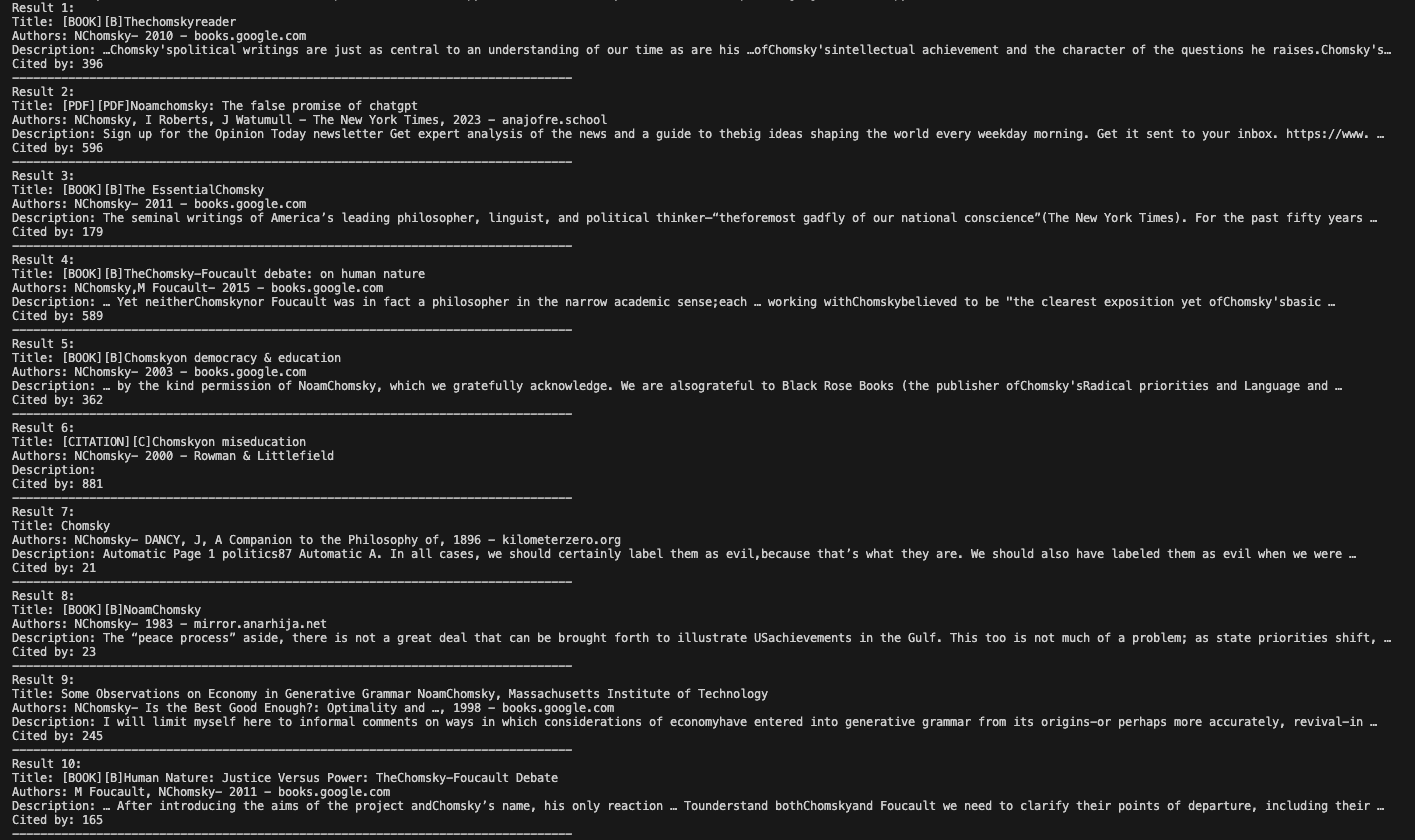
在这个例子中,我们使用“chomsky”作为我们的搜索词。诺姆·乔姆斯基(Noam Chomsky)的大量作品意味着他的名字将产生丰富的出版物、引文数量和相关链接,展示该脚本如何处理不同的结果条目。
完整的Google Scholar抓取代码
下面是我们在本教程中组装的完整Python脚本。您可以复制、运行它,并将其调整到您自己的Google Scholar抓取项目中。
在编码环境中运行它后,结果如下:
抓取Google Scholar的高级提示和替代方案
一旦你运行了一个基本的抓取器,你可能会开始遇到更高级的挑战,比如处理动态内容、缩放抓取量或处理偶尔的访问限制。以下是一些额外的技术和解决方案,可以提高您的谷歌学术抓取能力:
处理JavaScript渲染的内容
尽管Google Scholar的大部分主页都是静态HTML,但一些边缘情况或未来的变化可能会引入JavaScript渲染的元素。Selenium、Playwright或Puppeteer等工具可以模拟完整的浏览器环境,使抓取甚至动态加载的内容变得容易。
添加强大的错误处理和重试逻辑
大规模抓取时,网络故障、临时服务器问题或偶尔失败的请求是不可避免的。在您的scraper中构建重试机制,以自动重试失败的请求,最好是随机退避间隔。这有助于在长时间的抓取过程中保持稳定性。
保存并继续您的抓取会话
如果你打算抓取大量页面,可以考虑实施一个系统,在每几页或结果后保存你的进度。这样,如果您的scraper中断,您可以轻松地从中断的地方继续,而不会重复工作或丢失数据。
使用像Decodo的网络抓取 API这样的一体式抓取解决方案
为了提高效率和可靠性,可以考虑使用Decodeo的网络抓取 API。它结合了一个强大的网络抓取,可以访问125M多个住宅、数据中心、移动和ISP代理,无需自己管理IP轮换。其主要特征包括:
- 动态页面的JavaScript渲染;
- 每秒无限制请求,无需担心限制;
- 195+个地理目标位置,用于精确抓取;
- 7天免费试用,无需承诺即可测试服务。
总结
到目前为止,您已经了解到可以使用Python通过Requests和BeautifulSoup库访问Google Scholar,并且使用可靠的代理对于成功设置至关重要。不要忘记遵循最佳实践,并考虑使用简化的工具来提取所需的数据。
关于作者

Dominykas Niaura
技术文案
Dominykas 在他的写作中独特地融合了哲学洞察力和专业技术知识。他的职业生涯始于电影评论家和音乐行业的文案,现在他是一位将复杂的代理和网络搜索概念变得通俗易懂的专家。
通过 LinkedIn 与 Dominykas 联系。
Decodo 博客上的所有信息均按原样提供,仅供参考。对于您使用 Decodo 博客上的任何信息或其中可能链接的任何第三方网站,我们不作任何陈述,也不承担任何责任。

