AI+Decodo: 如何利用 AI 技术优化全球价格监测效率?
在现代电商环境中,价格监控已成为商家和消费者的刚需。然而传统的网页爬虫面临着反爬虫机制越来越严格、网页结构复杂多变、IP被封禁等诸多挑战。本文将详细介绍如何结合AI智能分析与高质量代理池,构建一个既稳定又智能的电商价格监控系统。
Kristina Selivanovaite
最后更新: 10月 16日, 2025年
4 分钟阅读

一、技术背景与挑战分析
传统爬虫的痛点
现代电商网站的反爬虫机制日趋完善,传统爬虫面临以下核心挑战:
- 网络访问层面的严格限制:IP 频繁访问被封禁、User-Agent 识别与拦截,导致数据获取困难。
- 页面结构的动态复杂性:动态 JavaScript 渲染内容、页面结构频繁变更,传统静态解析方式已无法适应。
- 数据提取的多样性挑战:价格格式千变万化、库存状态表达不统一,不同平台数据呈现差异大,需更智能的识别能力。
不同平台的数据呈现方式差异巨大,需要更智能的识别和解析能力。
解决方案架构
为了解决这些问题,我们设计了一个"AI + 代理池"的智能抓取架构:
核心设计思路:
- 代理池负责网络身份管理,实现IP轮换和访问伪装
- AI负责内容理解分析,智能识别和提取关键信息
这种架构将网络访问和内容分析分离,各司其职,大幅提升了系统的稳定性和智能化水平。
二、实战开发:构建智能监控系统
环境准备与核心依赖
首先需通过 pip 安装相关库:
项目构建需要合理的技术栈组合:
关键配置优化:
这些配置能够有效减少网络请求中的干扰因素,提升系统稳定性。
Decodo代理池管理核心实现
代理池是整个系统的网络基础,我们选择Decodo作为代理服务提供商,Decodo代理的核心优势是:
- 高匿名度IP,有效规避识别
- 多地域节点覆盖
这确保了访问的稳定性和隐蔽性,大幅提升抓取成功率。
这些代理节点不仅分布在不同端口,还具备动态切换能力,当某个代理出现响应延迟或连接失败时,系统会自动将其从可用列表中移除,确保始终使用状态最佳的代理进行网络请求。获取这些 Decodo 代理的方式首先需要我们注册Decodo平台的账户,然后其控制台会出现在我们眼前,在控制台左侧导航栏找到 “静态住宅代理”。在页面上方 “选择代理类型” 区域,确认选中 “按 IP 付费”(与少数用户共享的 IP)这一选项。
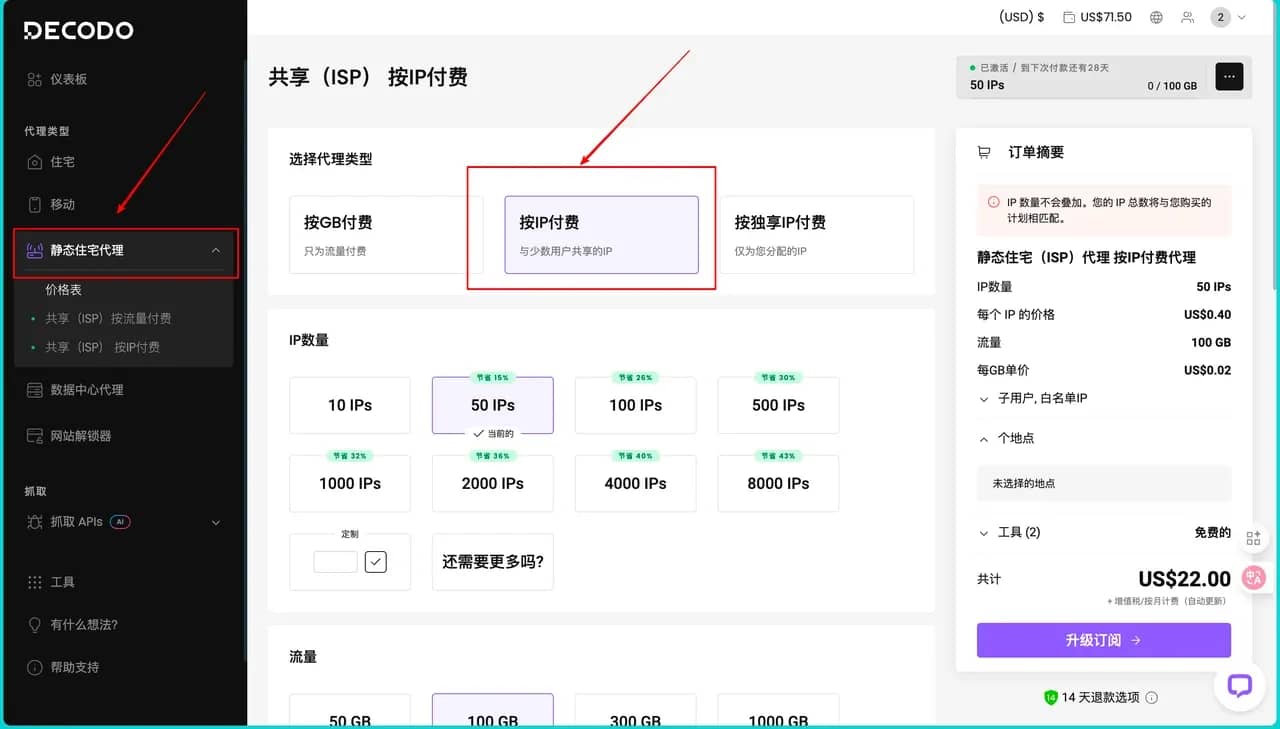
然后在 “IP 数量” 板块,我们根据需求选择预设的 IP 数量,因为我下面的项目中需要的IP 数量并不是很多,所以这个地方我仅需要选择50个即可,同时我们也可以根据自己需要勾选定制输入自定义数量。同理在 “流量” 板块,我们也直接根据需要选择所需的流量额度即可完成。
右侧 “订单摘要” 会实时显示所选配置的费用明细,确认 IP 数量、流量、单价等信息无误后,点击订阅即可完成,获取对应的代理资源。然后直接会弹出我们刚才购买好的界面,这里会显示出我们需要的用户的代理地址用户名以及密码:
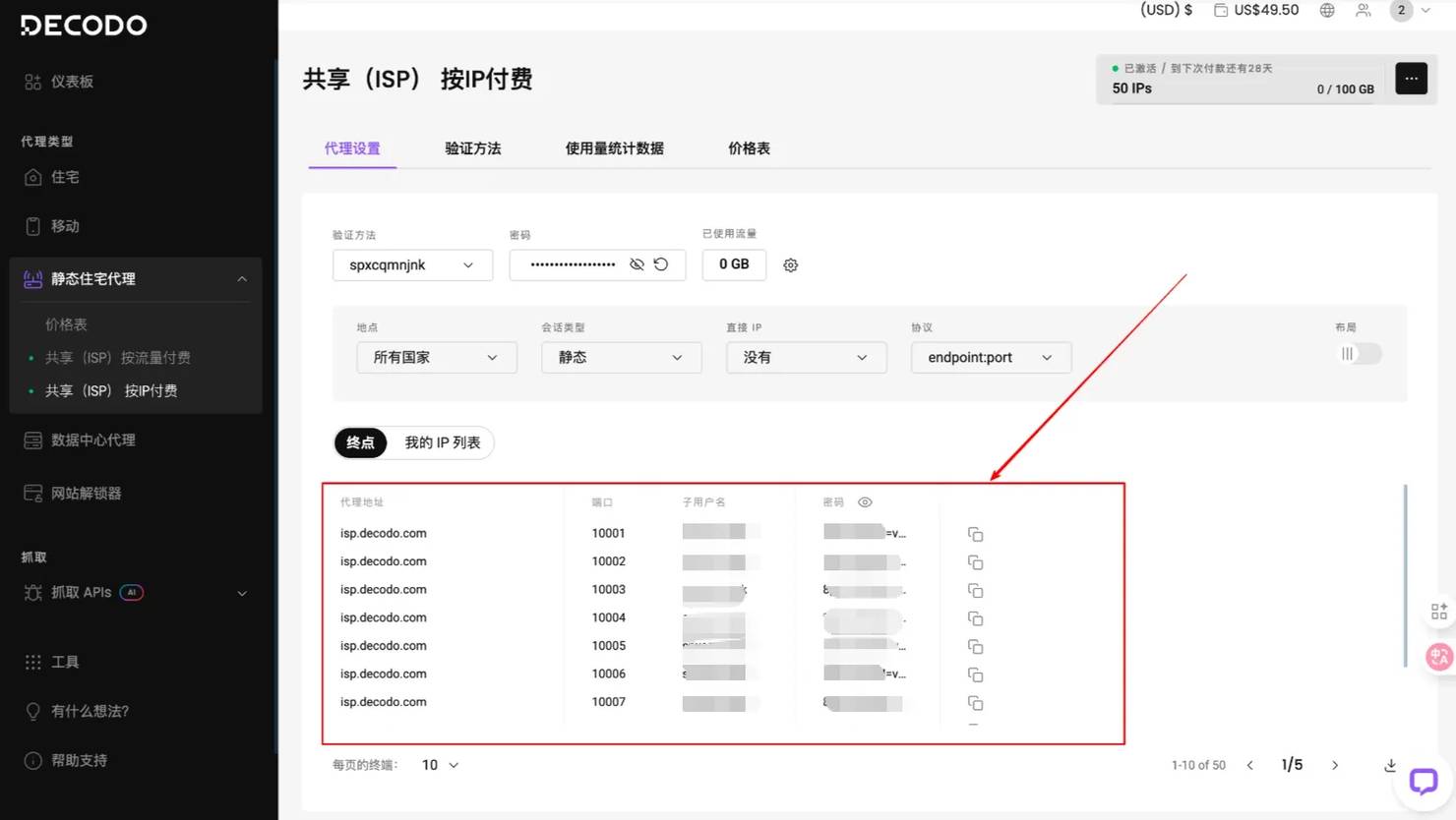
将如上的用户信息输入我们预订好的代码中,如下面所示,这里我并不展示所有的用户,大家可以参考这个格式去实现自己的配置
代理管理的核心设计理念就是轮询机制避免单点过载,同时要达到失效代理实时清理,这样通过智能化的代理调度,就可以确保我们的系统具有高可用性和稳定性。
AI内容分析引擎
这是AI分析内容的主要部分,负责理解复杂的电商页面结构,AI分析的关键优势:智能识别页面主要内容,同时自动过滤广告和无关信息。AI模型能够理解页面的语义结构,准确提取商品核心信息。
大家在设置的时候可以参考我的提示词给 AI 明确的指令,这样能让 AI 更精准地理解需求,减少无效输出。下面是完整的工具类代码,已针对 OpenAI API 版本兼容和密钥安全配置做了优化:
OpenAI所需要的API需要我们去访问官网:官网,完成注册之后进入API Keys页面,去创建我们自己的新密钥,然后设置合理的使用限额避免超支,这里我们需要的GPT-3.5-turbo价格约为$0.002/1K tokens。
智能请求管理与重试机制
结合代理池和AI分析,构建智能的网页获取系统:
智能重试的核心特性:
- 根据HTTP状态码智能判断
- 指数退避避免频繁重试
这种机制能够有效应对各种网络异常,提升整体成功率。
完整的监控流程实现
将所有组件整合,构建完整的商品监控流程:
监控流程的优势:
- 网络层和分析层职责分离
- 完整的错误处理和日志记录
每个环节都有详细的状态跟踪,便于问题定位和系统优化。
三、运行结果与性能分析
完整的工作流程
创建 PriceMonitor 主类,将代理管理、AI分析、网页抓取等功能模块有机整合,形成了一个完整的工作流程。让整个监控系统真正可以很简单的运行起来,现在我们只需配置好Decodo代理和OpenAI API密钥,就能立即开始监控心仪商品的价格变化,实现自动的电商价格追踪:
系统运行效果
通过实际测试,系统表现出了优异的性能,可以快速获取我们需要的商品信息,成功率百分之百。AI模型能够准确识别商品名称、价格、库存状态,自动过滤页面中的广告和推荐内容,同时提供稳定的网络访问,智能重试机制应对临时网络问题,运行结果如下所示,把我们需要的产品信息都获取出来:
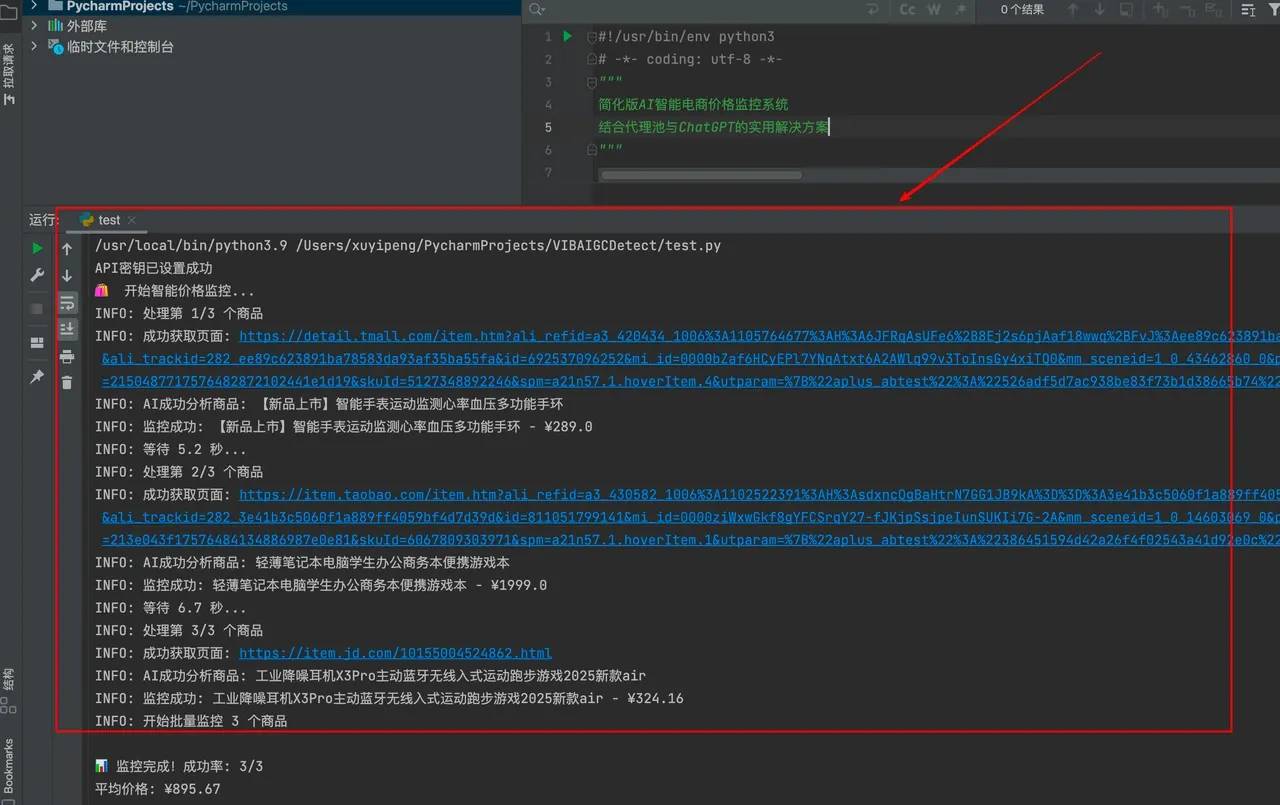
实际应用效果
在实际应用中,系统的价格预警功能展现出了强大的实用性,其核心设计围绕精准监控与及时提醒展开,形成了一套完整的智能预警机制。依托代理保障网络访问稳定,借助 AI 精准提取商品信息,当监控到商品当前价≤用户设的目标价时,会立即触发预警,还支持 CSV、JSON 格式存储数据,方便后续分析。
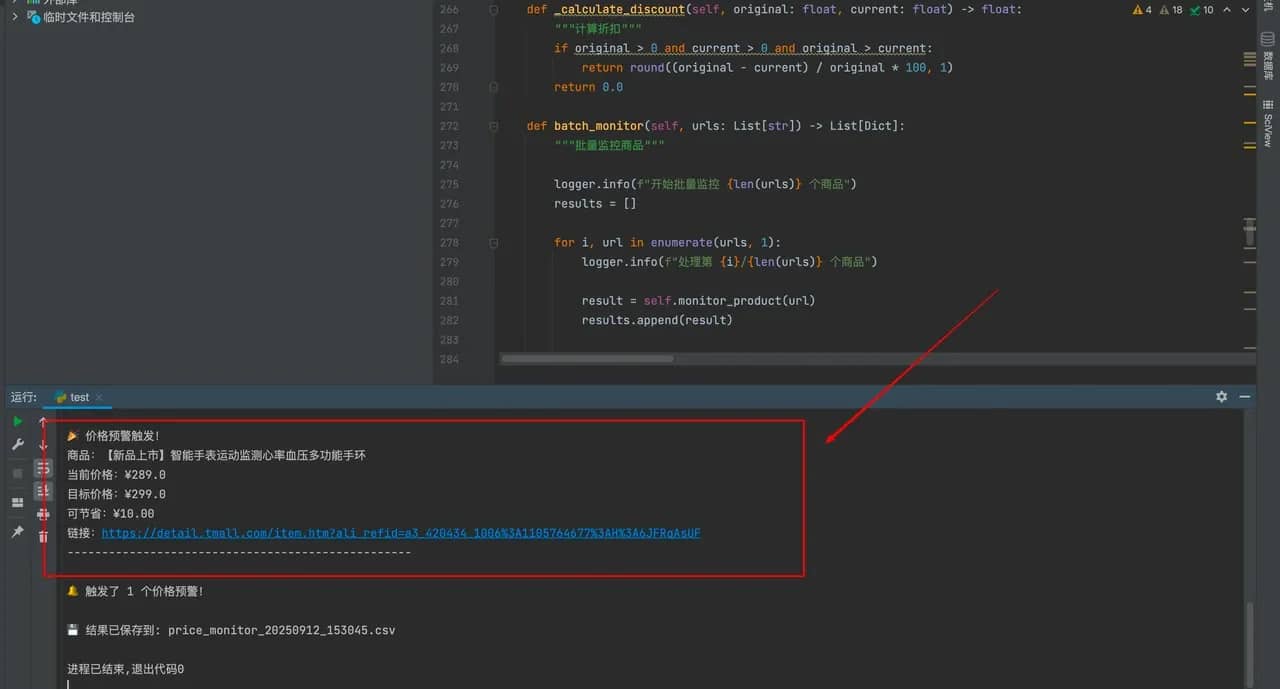
四、总结与展望
本项目成功整合了AI技术和代理池技术,实现了以下技术突破:
智能化水平显著提升
- AI理解页面结构,无需预定义解析规则
- 自适应各种电商平台的页面变化
网络访问稳定性优化
- Decodo代理池提供高质量IP资源
- 智能重试和故障转移机制
通过AI和代理池的深度融合,我们成功构建了一个既智能又稳定的价格监控系统。Decodo代理服务在其中发挥了关键作用,为系统提供了可靠的网络访问基础。这种技术组合不仅解决了传统爬虫的痛点,更为未来的智能数据抓取技术发展指明了方向。随着AI技术的不断进步和代理服务质量的持续提升,相信这种"AI+代理池"的模式将在更多领域得到广泛应用,为数据驱动的商业决策提供更强大的技术支撑。
关于作者

Kristina Selivanovaite
Decodo 德口多专家专栏: 品牌保护专家 Kristina Selivanovaite
Kristina 是国际关系和外交方面的专家,拥有硕士学位,并对全球数字访问桥梁有着浓厚的兴趣。凭借她的学术背景和全球视野,Kristina 为我们的中国读者量身定制了富有洞察力的内容,涵盖的主题包括网络搜刮、代理以及绕过各种网络限制的方法。
通过 LinkedIn 与 Kristina 联系。
Decodo 博客上的所有信息均按原样提供,仅供参考。对于您使用 Decodo 博客上的任何信息或其中可能链接的任何第三方网站,我们不作任何陈述,也不承担任何责任。