∞
每秒请求次数
100+
现成模板
100%
成功率
195+
全球各地
7 天
免费测试
探索我们针对任何需求的计划
每种计划您都可以访问
API 游乐场
预制刮板
代理管理
可扩展计划
地理定位
14 天退款选项
SSL安全支付
您的信息受256位SSL加密保护
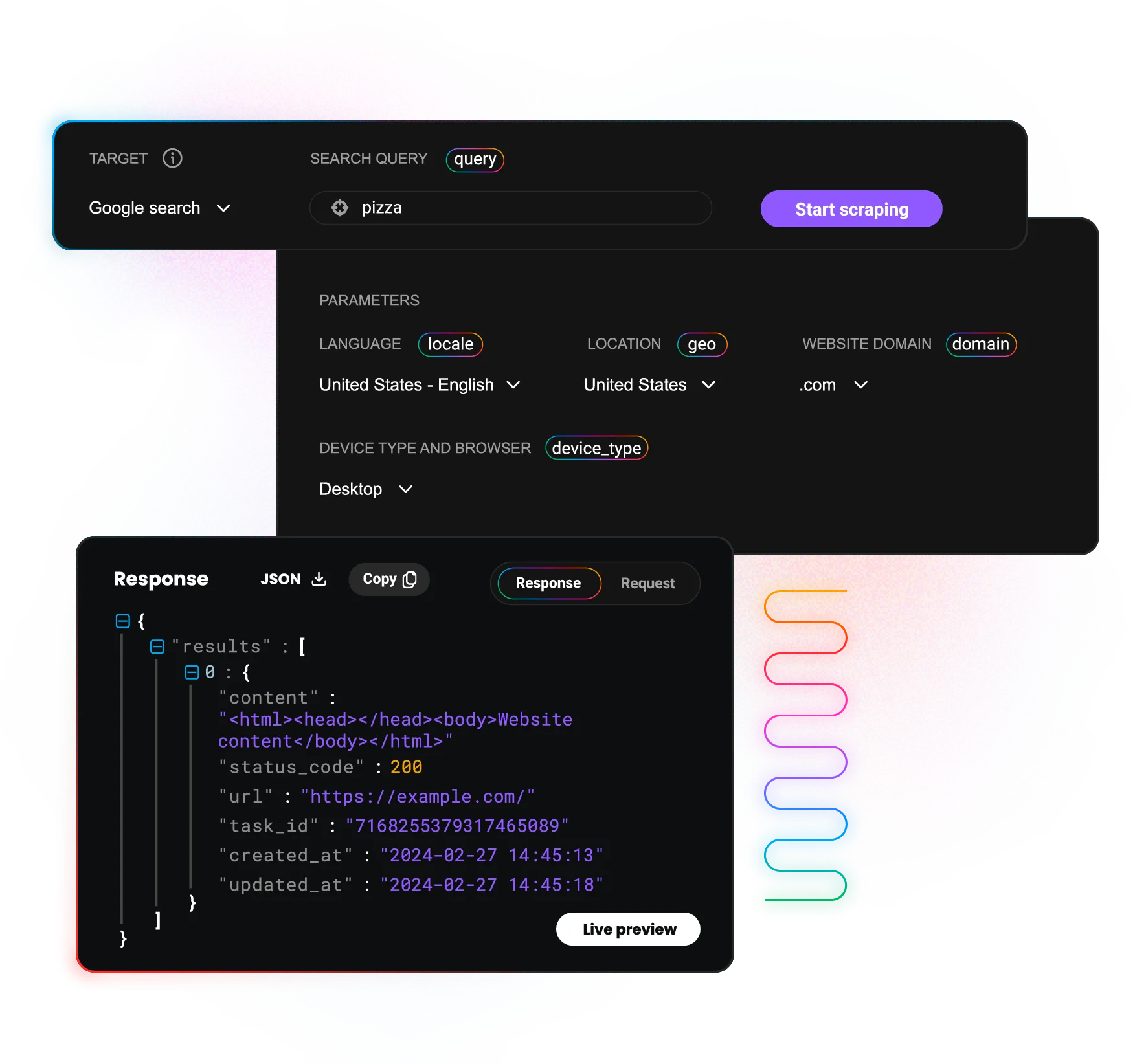
使用我们的 SERP抓取 API 获得结构化见解
通过灵活的数据输出、按需结果等收集任意规模的结构化搜索引擎结果页面数据。
灵活的输出选项
在原始 HTML 或 JSON 结果以及在表中解析的结果之间进行选择以满足你的需求。
任务安排
提前安排你的抓取任务,并在完成后通过电子邮件收到通知。
轻松集成
使用 GitHub、Postman 集合和我们的快速入门指南上的代码示例进行设置。
实时或按需结果
为你的目标选择同步或异步请求。
先进的反机器人保护
我们的抓取 API 集成了浏览器指纹以实现无缝数据收集。
现成抓取模板
借助我们可定制的现成抓取,快速访问实时数据。
几秒钟内即可开始抓取

快速入门资源
通过我们的 Github 使用 Python、PHP 和 Node.js 等流行编程语言的详细代码示例简化你的开发,或者查看我们的快速入门指南以获取设置技巧。想变得更容易吗? 我们可定制的预配置参数的现成抓取将为你完成所有繁重的工作
浏览我们的其他产品
媒体对我们的评价
我们很高兴得到超过 50,000 名客户和业界的支持






精选于:
Decodo博客
我们的博客是了解我们的解决方案或为你的下一个项目获取新想法的完美场所。
最近

使用抓取 API 可靠高效地提取亚马逊数据
在当今的全球电子商务环境中,从产品研究到竞争对手分析,亚马逊数据的访问都发挥着至关重要的作用。对于开发人员和技术团队,尤其是中国的开发人员和技术团队来说,构建可扩展且不易被察觉的亚马逊搜索解决方案已成为一种战略需要。
不过,要搜索亚马逊并不简单。亚马逊的基础架构通过速率限制、IP 黑名单、浏览器指纹识别和验证码来积极防御僵尸程序。传统的搜索方法(依赖静态代理或无头浏览器)很难保持长期的可靠性或性能。
本文探讨了一种更可持续的方法:使用受管理的抓取 API 来持续提取亚马逊数据。Decodo 为亚马逊等电子商务平台提供完全托管的抓取 API,通过单个 API 调用提供自动数据收集,如产品详细信息、定价、评论和卖家信息,而无需构建或维护自己的刮板基础架构。
Kristina Selivanovaite
7月 23日, 2025年
5 分钟阅读
最受欢迎

为什么不应该使用虚假 IP 和免费代理?
当我们扩展业务、进行研究或只是悠闲漫步时,了解在线安全始终是个好主意。无论你关注 Web 浏览器的原因是什么,匿名和隐私都是这里非常重要的两个因素。
问题是任何浏览器、网站、系统或网络都可以看到我们的 IP 地址。其中一些甚至可能会记录你的 IP 地址并对其进行跟踪。很吓人,哈?如果你知道一两个关于免费代理、VPN 服务和虚假 IP 的细节,你就知道这不是真的
在这篇博文中,我们将讨论使用免费软件、虚假 IP 的危险,以及使用 IP 信息的非法方面。拿一杯热咖啡(或茶),开始吧!
James Keenan
5月 08日, 2023年
6 分钟阅读

住宅网络代理网络如何帮助抓取亚马逊
美国公司亚马逊及其创始人(世界上第二富豪,也可能在世界最不受欢迎的人中排名之一位)不需要冗长的介绍。今天的亚马逊是电子商务、云存储、数字流媒体、人工智能、物流等领域的巨头。
我们将专注于亚马逊的电子商务。简而言之,它是世界领先的在线零售商。根据某些统计数据,90% 的购物者会在亚马逊上比较商品的价格和质量,即使他们在另一个网站上找到相同的商品。因此,如果你是卖家,你将有兴趣关注亚马逊的趋势以适应市场。
本文将介绍抓取亚马逊的好处以及如何正确地进行抓取。
James Keenan
5月 08日, 2023年
6 分钟阅读

常见问题解答
什么是 SERP抓取 API?
SERP抓取 API 是一种应用程序编程接口,用于定位搜索引擎结果页面。我们的 SERP抓取 API 是一种从搜索引擎收集数据的工具。
我可以使用 SERP抓取 API 抓取哪些搜索引擎?
借助我们的 SERP抓取 API,你可以定位 Google、Bing、百度、Yandex。
什么是现成抓取?
现成抓取是我们抓取 API 中预先配置的工具,旨在轻松快速地收集数据。它们消除了对广泛的技术知识、自定义抓取开发和代理管理的需求,使它们成为寻求低代码解决方案的用户的理想选择。通过使用现成的抓取工具,你可以有效地访问和构建大型数据集。
SERP抓取 API 需要多长时间才能返回结果?
需要几毫秒!我们实时为你提供结果,因此我们的抓取 API 甚至可以满足最不耐烦的用户。
SERP抓取 API 合法吗?
合法,抓取搜索引擎结果页面是合法的,因为 SERP 数据是公开的。
我们的 SERP抓取 API 的常见用例有哪些?
SERP抓取 API 主要用于 SEO 和市场研究目的。如果你正在构建解决方案并需要更多高级功能(例如跟踪实时排名),我们的工具会很有帮助。这就是为什么它非常适合有定制需求的大型企业。